Создание ядра. Собираем ядро Linux
Если пользователи часто посещают сайт с мобильных телефонов, то наиболее эффективным способом монетизировать этот трафик будет использование партнерки мобильных приложений. Участие в этой партнерской программе подразумевает плату за действие, а именно, за установку мобильных приложений. Этот метод монетизации зачастую используют не только для сайтов, но и для блогов, сообществ в Вконтакте, Facebook и других социальных сетях. Главной задачей вебмастера или администратора сообщества является реклама ссылок на мобильные приложения и стимулирование пользователей переходить по ним, скачивать и устанавливать эти приложения. Заработок вебмастера зависит от количества установок приложений, а также от того, насколько удачно он подберет партнерскую программу.
ОСОБЕННОСТИ РАБОТЫ С ПАРТНЕРКАМИ МОБИЛЬНЫХ ПРИЛОЖЕНИЙ
Мобильные партнерки, как правило, устроены таким образом, что плату можно получить лишь за одну установку приложения на одном и том же телефоне. Это делается с целью предотвратить мошенничества и случаев многоразовой установки приложения с последующим его удалением. Также некоторые устанавливают ограничения для сайтов, у которых невысокое качество трафика или же трафик не соответствует установленным требованиям. Стоимость установки приложений варьируется от нескольких рублей до нескольких сотен рублей. Ведущие мобильные партнерки осуществляют выплаты довольно часто (в день подачи заявки или в течение трех дней), а также предлагают массу возможностей для более простой и удобной работы вебмастера.
НА ЧТО НУЖНО ОБРАЩАТЬ ВНИМАНИЕ ПРИ ВЫБОРЕ МОБИЛЬНОЙ ПАРТНЕРКИ?
Все партнерские программы имеют не только различные условия регистрации и допуска для участия, но и ряд других особенностей, на которые стоит обратить внимание. Так, в первую очередь, стоит ознакомиться с ассортиментом мобильных приложений и ценами на их установку. Возможно, в данной партнерке попросту нет приложений, которые могли бы заинтересовать посетителей вашего сайта. Также вас может не устроить оплата, минимальная сумма для вывода или другие условия сотрудничества с партнеркой.
Изучение разных мобильных партнерок и сравнение условий потребует немалых усилий, но, благодаря специальным сервисам, сделать это намного проще. Мы поможем вам найти оптимальные варианты монетизации трафика и заработать на установке мобильных приложений.
В прошлой статье я вам рассказал, но, а сегодня пришло время рассказать о том, как составить семантическое ядро сайта при помощи специальных программ и серверов.
Наступает лето и как-то все труднее и тяжелее становиться вести блог, вот и результат статьи выходят редко что вас наверняка не радует. Не правда ли?
Честно сказать дело вовсе не в летней поре, а в моей «глупости» создания блога на начальном этапе. В общем, я при создании блога отталкивался от своих мыслей, а не от запросов пользователей. В общем, получилось так, что я сам себе отвечал на вопросы, смешно.
В одном из прошлых своих постов, я уже, как то писал для чего нужно СЯ сайту и что это такое, где раскрыл основу основ его создания, пора бы, наверное, и к практике создания семантического ядра перейти.
как создать семантическое ядро для сайта
В прошлой статье я в основном рассказывал теорию, но как показывает практика не всегда все пользователи понимают такой материал, так что представляю пошаговую инструкцию, которую можно взять за основу и сделать своё семантическое ядро без особых усилий. Да именно за основу, так как прогресс не стоит на месте и, возможно, уже есть более продвинутые способы создания ядра для сайта.
Ищем конкурентов для составления семантического ядра сайта
Итак, первым делом мы должны определиться, про что и о чём будет наш будущий сайт. Я возьму за основу тему «экология окружающей природы» и подберу к ней ключевые слова. Для определения основных ключей я возьму сайт конкурента находящейся на первых местах и Google.
Как вы понимаете я возьму за основу первые три сайта в выдаче Яндекс.
сезоны-года.рф
zeleneet.com
biofile.ru
Отбираем запросы конкурентов - автоматически
На этом шаге нам хорошо подойдёт любой сайт, который может автоматически определить запросы сайта, подходящие для его продвижения в топ. Я предпочитаю использовать , какой вы предпочтёте сервер - это сугубо ваше мнение, о котором вы можете написать мне в комментариях и обсудить.
Добавляем нашего донора, а не наш сайт!
Как вы уже догадались я взял один из трёх сайтов, - вы же должны взять несколько. Жмём далее…
Как видите, я отобрал только первые 10 запросов для наглядного примера. Вы должны собрать как можно больше ключевых слов также не поленитесь подумать, как вы спросили у гугла, чтоб найти ответ на ваш вопрос, которые собираетесь размещать в интернете на своём блоге или сайте. Переходим к следующему этапу формирования семантического ядра своими руками.
Как вы уже поняли вам осталось только экспортировать базу ключевых слов и перейти к следующему шагу на пути создания семантического ядра сайта, который вы сделаете самостоятельно. Не забываете проставить галочки на ключевых словах, которые пытаетесь сохранить в файле exel.
Отбираем НЧ СЧ и ВЧ запросы
На этом этапе нам поможет сервер, осторожно партнерская ссылка, зарегистрироваться в rookee.ru. Переходим на него и создаём новую рекламную кампанию используя сайт нашего конкурента.
Добавляем сайт и следуем пошаговой инструкции интернет ресурса.
Теперь нужно немного подождать, чтоб робот отсканировал сайт и дал вам наиболее интересные запросы, которые вы также можете применить впоследствии. Вот мой результат.
Как видите, система нашла 299 запроса, но они меня не интересуют и я просто возьму их удалю и добавлю те 10, которые мне дал seopult на первом этапе. Кстати, один запрос должен оставаться, иначе не сможете все удалить. У меня после удаления получилось так. Когда я добавлю основную базу запросов, я этот ключ удалю, чтоб он мне не мешал, так как он для меня не актуален. Теперь добавляем запросы, которые получили ранее.
У меня после удаления получилось так. Когда я добавлю основную базу запросов, я этот ключ удалю, чтоб он мне не мешал, так как он для меня не актуален. Теперь добавляем запросы, которые получили ранее.
Теперь нам нужно перейти в папку «запросы» и немного подождать, когда запросы просканирует поисковый робот. У меня в итоге вышло так, что все слова оказались НК (низкоконкурентными), которые мне вполне подходят для создания сайта и привлечения первых читателей на блог.
Если у вас есть слова со значением ВК (высокая конкуренция) или СК (средняя конкуренция), то на первом этапе формирования ядра вам следует от них отказаться и выбрать только низкую конкуренцию.
Экспортируем слова и переходим к следующему завершающему шагу. Так как у меня все слова по низкой конкуренции я ничего не удалял, у вас, возможно, другая ситуация. Но я вас убедительно прошу удалить средне и высоко конкурентные запросы, так как это лишние ваши затраты.
Составляем семантическое ядро для сайта
Для завершающего этапа нам понадобится программа Key Collector,я буду использовать её бесплатный прототип, который вы легко можете найти в интернете. Название этой программы я, пожалуй, оставлю вам в виде домашнего задания. Итак, открываем программу и вписываем свой найденные ключи, у меня их пока 9 штук.
Как мы видим, что из 9 запросов нам лучше писать про прибор для измерения влажности воздуха. Это пример с одним ключевым словом, которое актуально под НЧ запрос на указанную тематику.
Не забываете, что программа способна также подобрать 1 тыс. слов по основному запросу с его словоформами, для этого просто впишите слова в красную вкладку «пакетный сбор слов из Яндекс worstat».
После того как вы отберёте максимальное количество релевантных слов не забудьте их отсортировать по значимости начиная с меньшего. Старайтесь также делать хорошую перелинковку вашей статье, - это вызовет улучшение поведенческих фактов на вашем ресурсе.
Ну вот и все, что-то я затянул с работой. А вы как делаете СЯ для своего интернет-магазина? напишите мне об этом в комментариях.
P.S. Вы также можете получать мои новые статьи на почту просто подписавшись на rss рассылку и узнавать о моих секретах и методах первыми. А вы, как составляете семантическое ядро сайта? Напишите, мне о своем способе в комментариях, подискутируем.
Статья о том, как составить семантическое ядро самостоятельно, чтобы ваш интернет-магазин был на первых позициях выдачи поисковых систем. Процесс подбора ключевых слов – не такой уж и простой. Он потребует внимательности и относительно много времени. Но если вы готовы двигаться вперед и развивать свой бизнес, эта статья для вас. В ней подробно рассказывается о методах сбора ключевых слов, а также о том, какие именно инструменты могут вам помочь в этом.
Ответ банален - чтобы сайт «полюбили» поисковые машины. И чтобы при запросе пользователей по конкретным ключевым словам выдавали именно ваш ресурс.
И формирование семантического ядра – первый, но весьма важный и уверенный шаг на пути к цели!
Следующий шаг – создание своеобразного скелета, что подразумевает под собой распределенных подобранных «ключей» по определенным страницам сайта. И лишь после этого следует переходить на новый уровень – написания и внедрения статей, тегов.
Отметим, что в сети представлено несколько вариантов определения понятия семантического ядра (далее – СЯ).
В целом они сходны и если обобщить все, то можно сформировать следующее: набор ключевых слов (а также сопутствующих словосочетаний и форм) для продвижения сайта. Такие слова точно характеризуют направленность сайта, отображают интересы пользователей и соответствуют деятельности компании.
В нашей статье приведен пример формирования СЯ для интернет-магазина постельного белья. Весь процесс разделен на пять последовательных этапов.
1) Собираем базовые запросы
В данном случае речь идет обо всех фразах, которые будут соответствовать направлению деятельности магазина. Поэтому так важно максимально точно продумать те фразы, что наилучшим образом характеризуют товары, представленные в каталоге.
Конечно, сделать это иногда бывает непросто. Но на помощь придет правая графа Wordstat.Yandex – в ней указываются словосочетания, которые чаще прочих вводятся пользователями при использовании выбранной вами фразы.
Для того чтобы получить результаты, введите в строке сервиса нужное вам словосочетание и кликните по кнопке «Подобрать».

Дабы не копировать все запросы вручную, рекомендуем использовать расширение Wordstat Helper, созданное специально для браузеров Mozilla Firefox и Google Chrome. Такое дополнение существенно упростит работу с подбором слов. Как оно работает – смотрите на скрине ниже.

Отобранные слова сохраните в отдельном документе. После проведите мозговой штурм и добавьте в него те фразы, которые придумаете.
2) Как расширить СЯ: три варианта
Первый этап относительно простой. Хотя и потребует от вас внимательности. Но второй – активной мозговой деятельности. Ведь каждая отдельно выбранная фраза – это основа будущей группы поисковых запросов, по которым вы будете продвигаться.
Чтобы собрать такую группу, необходимо использовать:
- синонимы;
- перефразирования.
Чтобы не «загрузнуть» в этом этапе, воспользуйтесь специальными приложениями или сервисами. Как это сделать – подробно описано ниже.
Как расширить СЯ с помощью планировщика ключевых слов Google
Переходим в тематический раздел (он называется Планировщик ключевых фраз) и набирает те фразы, которые наиболее точно характеризуются интересующую вас группу запросов. Прочие параметры не трогаете и кликаете по кнопке «Получить … ».

После этого просто скачиваете полученные результаты.

Как расширить СЯ с помощью Serpstat (ex. Prodvigator)
Вы также можете использовать другой подобный сервис, с помощью которого проводит анализ конкурентом. Ведь именно конкуренты представляют собой оптимальное место, где можно получить требуемые вам ключевые слова.
Сервис Serpstat (ex. Prodvigator) позволяет точно определить, по каким именно ключевым запросам ваши конкуренты выбились в лидеры поисковых систем. Хотя есть и другие сервисы – каким именно пользоваться, решайте сами.
Для того чтобы подобрать поисковые запросы, вам нужно:
- ввести один запрос;
- указать интересующий вас регион продвижения;
- кликнуть по кнопке «Поиск»;
- а когда он завершится – выбрать опцию «Поисковые запросы».

После этого кликните по кнопке «Экспорт таблицы».
Как расширить СЯ с помощью Key Collector/Словоёб
У вас большой магазин с огромным количеством товаров? В такой ситуации вам понадобится сервис Key Collector .
Хотя если вы только начинаете познавать науку подбора ключевых слов и формирования семантического ядра, рекомендуем обратить внимание на другой сервис – с неблагозвучным названием Словоеб . Его преимущество состоит в том, что он полностью бесплатный.
Скачайте приложение, перейдите в настройки Яндекс.Директ и введите логин/пароль от почтового ящика Яндекса.

После этого:
- откройте новый проект;
- кликните по вкладке Данные;
- там нажмите на опцию Добавить фразы;
- укажите интересующий вас регион продвижения;
- введите запросы, которые были сформированы ранее.

После этого приступайте к сбору СЯ из Wordstat.Yandex. Для этого:
- перейдите в раздел «Сбор данных»;
- затем – нужно выбрать раздел «Пакетный сбор слов из левой колонки»;
- перед вами на экране появится новое окно;
- в нем – сделайте так, как указано на скрине ниже;

Отметим, что Key Collector отличный инструмент для объемных, крупных проектов и с его помощью легко организовать сбор статистических данных по сервисам, анализирующим «работу» сайтов-конкурентов. Например, к таковым сервисам относятся следующие: SEMrush, SpyWords, Serpstat (ex. Prodvigator) и многие другие.
3) Удаляем лишние «ключи»
Итак, база сформирована. Объем собранных «ключей» — более чем солидный. Но если их проанализировать (в данном случае – просто внимательно почитать), выясниться, что далеко не все собранные слова точно соотносятся с тематикой вашего магазина. А потому по ним на сайт будут заходиться «не целевые» пользователи.
Такие слова нужно удалять.
Представляем еще один пример. Так, на сайте вы продаете постельное белье, но в вашем ассортименте нет просто ткани, из которой такое белье можно пошить. Поэтому, все, что касается тканей – нужно убирать.
Кстати, полный перечень таких слов придется формировать вручную. Тут уже никакая «автоматика» не поможет. Естественно, потребуется относительно много времени и чтобы ничего не пропустить, рекомендуем устроить полноценный мозговой штурм.
Отметим следующие виды и типы слов, которые будут неактуальны для интернет-магазинов:
- название и упоминание магазинов-конкурентов;
- города и регионы, в которых вы не работаете и куда не поставляете товары;
- все слова и фразы, в которых присутствуют «бесплатно», «старый» или «б у», «скачать» и т.п.;
- название бренда, который не представлен в вашем магазине;
- «ключи», в которых имеются ошибки;
- повторяющиеся слова.
Теперь расскажем, как удалить все ненужные вам слова.
Сформируйте список
Открываем сервис Словоеб, в нем выбираем раздел «Данные», а там переходим во вкладку «Стоп-слова» и «вбейте» в нее отобранные вручную слова. Интересно, что записать слова можно, как вручную, так и просто подгрузить файл с ними (если вы таковой подготовили).

Таким образом, вы сможете довольно быстро устранить из своего списка стоп-слова, не отвечающие тематике, особенностям магазина.
Быстрый фильтр
Вы получили своеобразную заготовку СЯ. Тщательно проанализируйте ее и приступайте к удалению ненужных слов вручную. Оптимизировать решение данной задачи поможет тот же сервис Словоеб. Вот последовательность действий, которые вам нужно выполнить:
- возьмите первое ненужное слово из вашего списка, к примеру, пусть это будет город Киев;
- вбейте его в поиск (на скрине – цифра 1);
- пометьте соответствующие строки;
- нажимая на них правой кнопкой мышки, удалите;
- нажмите Enter в поле поиска, дабы возвратиться к изначальному списку.

Повторяйте перечисленные действия столько, сколько придется, пока не пересмотрите наиболее возможный список слов.
4) Группируем запросы
Дабы понимать, каким образом проводить распределение слов по конкретным страницам, следует выполнить группировку всех отобранных вами запросов. Для этого следует сформировать так называемые семантические кластеры.
Под данным понятием подразумевается группа схожих по тематике, смыслу «ключей», которая оформляется в виде многоуровневой структуры. Допустим, кластер первого уровня – это поисковый запрос «постельное белье». А вот кластерами второго уровня будут поисковые запросы «одеяла», «пледы» и тому подобное.
В большинстве случаев определение кластеров осуществляется при мозговом штурме. Но важно отлично разбираться в ассортименте, особенностях своего товара, но также учитывать и то, каким образом построена структура конкурентов.
Следующее, на что нужно обязательно обратить особое внимание – на последнем уровнем кластера должны быть только те запросы, которые точно соответствуют единственной потребности потенциальных клиентов. То есть, конкретному виду товаров.
Тут вам на помощь снова придет все тот же сервис Словоеб и описанная выше опция Быстрого фильтра. Он поможет выполнить сортировку поисковых запросов по определенным категориям.
Чтобы выполнить такую сортировку вам нужно выполнить несколько простых шагов. Сначала в поисковой строке сервиса вводите ключевое слово, которое будет использоваться при наименовании:
- категории;
- посадочной страницы и т.д.
Например, это может быть бренд постельного белья. В полученных результатах пометьте фразы, которые подходят вам и скопируйте.
Те фразы, что вам не нужны, просто выделите правой кнопкой мыши и удалите.

В правой части меню сервиса сделайте новую группу, назвав ее соответствующим образом. Например, наименованием бренда.
Чтобы перенести выбранные вами фразы в эту часть вкладки, необходимо выбрать строку Данные и кликнуть по надписи Добавить фразы. Подробнее – смотрите скрин.

Нажав Enter в графе поиска, вы возвратитесь к изначальному списку слов. Проделайте описанную процедуру со всеми остальными запросами.
Все отобранные фразы система будет выдавать в алфавитной последовательности, что упрощает работу с ними – вы легко сможете определить, что именно можно удалить. Или же сгруппировать слова в определенную группу.

Добавим, что ручная группировка также требует достаточное количество времени. Особенно, если речь идет о слишком большом количестве ключевых фраз. Поэтому рекомендуем воспользоваться автоматизированными платными программами. К таковым относятся:
- Key Collector;
- Rush-Analytics;
- Just-Magic и другие.
Также имеется полностью бесплатный скрипт Devaka.ru. Кстати, обратите внимание, что часто приходится объеденять некоторые типы запросов.
Поскольку нет никакого смысла нагромождать на сайте огромное число категорий, отличающихся только такими названиями, как «Красивое постельное белье» и «Модное постельное белье».
Чтобы определиться с важностью каждой отдельной ключевой фразы для той или иной категории, достаточно просто перенести их в планировщик Google, как показано на скрине.

Таким образом, вы сможете определить, насколько востребован тот или иной поисковый запрос. Все их можно разделить на три категории, в зависимости от частности использования:
- высокочастотные;
- низкочастотные;
- среднечастотные;
- и даже микро-низкочастотные.

Однако важно понимать, что точных цифр, которые отображают принадлежность запроса к определенной группе, нет. Здесь следует ориентироваться на тематику, как самого сайта, так и запроса. В отдельном случае запрос с частотой до 800 в месяц может считаться низкочастотным. В другой же ситуации запрос с частотой до 150 будет являться высокочастотным.
Самые высокочастотные запросы из всех отобранных впоследствии будут вписаны в теги. А вот самые низкочастотные рекомендовано использовать для того, чтобы оптимизировать под них конкретные страницы магазина. Поскольку среди таких запросов будет низкая конкуренция, хватит просто наполнить такие подразделы качественными текстовыми описаниями, дабы страницы оказалась в первых рядах поисковой выдачи.
Все перечисленные выше действия позволят вам сформировать четкую структуру, в которой будут иметься:
- все необходимые и важные категории – чтобы сделать визуализацию «скелета» вашего магазина, воспользуйтесь дополнительным сервисом XMind ;
- посадочные страницы;
- страницы, в которых представлена важная для пользователя информация – например, с контактными данными, с описанием условий доставки и т.д.
Как расширить семантическое ядро: альтернативный метод
С развитием сайта, расширением магазина будет увеличиваться и СЯ. Для этого необходимо проводить мониторинг и сбор ключевых фраз в рамках каждой группы. Что существенно упрощает и ускоряет процесс расширения СЯ.
Для сбора схожих запросов, для подсказки, воспользуйтесь дополнительными сервисами, среди которых:
- Serpstat (ex. Prodvigator);
- Ubersuggest;
- Keyword Tool;
- и прочие.
Ниже на скрине представлено, как пользоваться сервисом Продвигатор.

Что делать после прохождения нашей инструкции
Итак, чтобы самостоятельно сформировать СЯ для интернет-магазина, вам необходимо выполнить целый ряд последовательных действий.
Начинается все с подбора ключевых слов, которые только могут использоваться при поиске ваших товаров и которые впоследствии станут основной группой запросов. Далее, воспользовавшись инструментами поисковых систем расширить семантическое ядро. Также для этого рекомендуется провести анализ сайтов-конкурентов.
Следующие шаги будут такими:
- анализ всех отобранных поисковых запросов;
- удаление запросов, которые не соответствуют смыслу вашего магазина;
- группирование запросов;
- формирование структуры сайта;
- постоянное отслеживание поисковых запросов и расширение СЯ.
Представленный в данной статье способ подбора СЯ для интернет-магазина – далеко не единственный верный и правильный. Существуют и другие. Но мы постарались представить вам наиболее удобный способ.
Естественно, для продвижения также важны такие показатели, как качество текстовых описаний, статей, тегов, структуры магазина. Но об этом мы поговорим в отдельном материале.
Чтобы не пропустить новые и полезные статьи, обязательно подпишитесь на нашу рассылку!
Вы еще не проходите тренинг, ? Запишитесь прямо сейчас и уже через 4 дня у вас будет свой сайт.
Если вы не сможете сделать его сами, мы сделаем его за вас!
Разработка ядра по праву считается задачей не из легких, но написать простейшее ядро может каждый. Чтобы прикоснуться к магии кернел-хакинга, нужно лишь соблюсти некоторые условности и совладать с ассемблером. В этой статье мы на пальцах разберем, как это сделать.
Привет, мир!
Давай напишем ядро, которое будет загружаться через GRUB на системах, совместимых с x86. Наше первое ядро будет показывать сообщение на экране и на этом останавливаться.
Как загружаются x86-машины
Прежде чем думать о том, как писать ядро, давай посмотрим, как компьютер загружается и передает управление ядру. Большинство регистров процессора x86 имеют определенные значения после загрузки. Регистр - указатель на инструкцию (EIP) содержит адрес инструкции, которая будет исполнена процессором. Его захардкоженное значение - это 0xFFFFFFF0. То есть x86-й процессор всегда будет начинать исполнение с физического адреса 0xFFFFFFF0. Это последние 16 байт 32-разрядного адресного пространства. Этот адрес называется «вектор сброса» (reset vector).
В карте памяти, которая содержится в чипсете, прописано, что адрес 0xFFFFFFF0 ссылается на определенную часть BIOS, а не на оперативную память. Однако BIOS копирует себя в оперативку для более быстрого доступа - этот процесс называется «шедоуинг» (shadowing), создание теневой копии. Так что адрес 0xFFFFFFF0 будет содержать только инструкцию перехода к тому месту в памяти, куда BIOS скопировала себя.
Итак, BIOS начинает исполняться. Сначала она ищет устройства, с которых можно загружаться в том порядке, который задан в настройках. Она проверяет носители на наличие «волшебного числа», которое отличает загрузочные диски от обычных: если байты 511 и 512 в первом секторе равны 0xAA55, значит, диск загрузочный.
Как только BIOS найдет загрузочное устройство, она скопирует содержимое первого сектора в оперативную память, начиная с адреса 0x7C00, а затем переведет исполнение на этот адрес и начнет исполнение того кода, который только что загрузила. Вот этот код и называется загрузчиком (bootloader).
Загрузчик загружает ядро по физическому адресу 0x100000. Именно он и используется большинством популярных ядер для x86.
Все процессоры, совместимые с x86, начинают свою работу в примитивном 16-разрядном режиме, которые называют «реальным режимом» (real mode). Загрузчик GRUB переключает процессор в 32-разрядный защищенный режим (protected mode), переводя нижний бит регистра CR0 в единицу. Поэтому ядро начинает загружаться уже в 32-битном защищенном режиме.
Заметь, что GRUB в случае с ядрами Linux выбирает соответствующий протокол загрузки и загружает ядро в реальном режиме. Ядра Linux сами переключаются в защищенный режим.
Что нам понадобится
- Компьютер, совместимый с x86 (очевидно),
- Linux,
- ассемблер NASM,
- ld (GNU Linker),
- GRUB.
Входная точка на ассемблере
Нам бы, конечно, хотелось написать все на C, но совсем избежать использования ассемблера не получится. Мы напишем на ассемблере x86 небольшой файл, который станет стартовой точкой для нашего ядра. Все, что будет делать ассемблерный код, - это вызывать внешнюю функцию, которую мы напишем на C, а потом останавливать выполнение программы.
Как сделать так, чтобы ассемблерный код стал стартовой точкой для нашего ядра? Мы используем скрипт для компоновщика (linker), который линкует объектные файлы и создает финальный исполняемый файл ядра (подробнее объясню чуть ниже). В этом скрипте мы напрямую укажем, что хотим, чтобы наш бинарный файл загружался по адресу 0x100000. Это адрес, как я уже писал, по которому загрузчик ожидает увидеть входную точку в ядро.
Вот код на ассемблере.
kernel.asm
bits 32 section .text global start extern kmain start: cli mov esp, stack_space call kmain hlt section .bss resb 8192 stack_space:Первая инструкция bits 32 - это не ассемблер x86, а директива NASM, сообщающая, что нужно генерировать код для процессора, который будет работать в 32-разрядном режиме. Для нашего примера это не обязательно, но указывать это явно - хорошая практика.
Вторая строка начинает текстовую секцию, также известную как секция кода. Сюда пойдет весь наш код.
global - это еще одна директива NASM, она объявляет символы из нашего кода глобальными. Это позволит компоновщику найти символ start , который и служит нашей точкой входа.
kmain - это функция, которая будет определена в нашем файле kernel.c . extern объявляет, что функция декларирована где-то еще.
Далее идет функция start , которая вызывает kmain и останавливает процессор инструкцией hlt . Прерывания могут будить процессор после hlt , так что сначала мы отключаем прерывания инструкцией cli (clear interrupts).
В идеале мы должны выделить какое-то количество памяти под стек и направить на нее указатель стека (esp). GRUB, кажется, это и так делает за нас, и на этот момент указатель стека уже задан. Однако на всякий случай выделим немного памяти в секции BSS и направим указатель стека на ее начало. Мы используем инструкцию resb - она резервирует память, заданную в байтах. Затем оставляется метка, указывающая на край зарезервированного куска памяти. Прямо перед вызовом kmain указатель стека (esp) направляется на эту область инструкцией mov .
Ядро на C
В файле kernel.asm мы вызвали функцию kmain() . Так что в коде на C исполнение начнется с нее.
kernel.c
void kmain(void) { const char *str = "my first kernel"; char *vidptr = (char*)0xb8000; unsigned int i = 0; unsigned int j = 0; while(j < 80 * 25 * 2) { vidptr[j] = " "; vidptr = 0x07; j = j + 2; } j = 0; while(str[j] != "\0") { vidptr[i] = str[j]; vidptr = 0x07; ++j; i = i + 2; } return; }Все, что будет делать наше ядро, - очищать экран и выводить строку my first kernel.
Первым делом мы создаем указатель vidptr, который указывает на адрес 0xb8000. В защищенном режиме это начало видеопамяти. Текстовая экранная память - это просто часть адресного пространства. Под экранный ввод-вывод выделен участок памяти, который начинается с адреса 0xb8000, - в него помещается 25 строк по 80 символов ASCII.
Каждый символ в текстовой памяти представлен 16 битами (2 байта), а не 8 битами (1 байтом), к которым мы привыкли. Первый байт - это код символа в ASCII, а второй байт - это attribute-byte . Это определение формата символа, в том числе - его цвет.
Чтобы вывести символ s зеленым по черному, нам нужно поместить s в первый байт видеопамяти, а значение 0x02 - во второй байт. 0 здесь означает черный фон, а 2 - зеленый цвет. Мы будем использовать светло-серый цвет, его код - 0x07.
В первом цикле while программа заполняет пустыми символами с атрибутом 0x07 все 25 строк по 80 символов. Это очистит экран.
Во втором цикле while символы строки my first kernel, оканчивающейся нулевым символом, записываются в видеопамять и каждый символ получает attribute-byte, равный 0x07. Это должно привести к выводу строки.
Компоновка
Теперь мы должны собрать kernel.asm в объектный файл с помощью NASM, а затем при помощи GCC скомпилировать kernel.c в другой объектный файл. Наша задача - слинковать эти объекты в исполняемое ядро, пригодное к загрузке. Для этого потребуется написать для компоновщика (ld) скрипт, который мы будем передавать в качестве аргумента.
link.ld
OUTPUT_FORMAT(elf32-i386) ENTRY(start) SECTIONS { . = 0x100000; .text: { *(.text) } .data: { *(.data) } .bss: { *(.bss) } }Здесь мы сначала задаем формат (OUTPUT_FORMAT) нашего исполняемого файла как 32-битный ELF (Executable and Linkable Format), стандартный бинарный формат для Unix-образных систем для архитектуры x86.
ENTRY принимает один аргумент. Он задает название символа, который будет служить входной точкой исполняемого файла.
SECTIONS - это самая важная для нас часть. Здесь мы определяем раскладку нашего исполняемого файла. Мы можем определить, как разные секции будут объединены и куда каждая из них будет помещена.
В фигурных скобках, которые идут за выражением SECTIONS , точка означает счетчик позиции (location counter). Он автоматически инициализируется значением 0x0 в начале блока SECTIONS , но его можно менять, назначая новое значение.
Ранее я уже писал, что код ядра должен начинаться по адресу 0x100000. Именно поэтому мы и присваиваем счетчику позиции значение 0x100000.
Взгляни на строку.text: { *(.text) } . Звездочкой здесь задается маска, под которую подходит любое название файла. Соответственно, выражение *(.text) означает все входные секции.text во всех входных файлах.
В результате компоновщик сольет все текстовые секции всех объектных файлов в текстовую секцию исполняемого файла и разместит по адресу, указанному в счетчике позиции. Секция кода нашего исполняемого файла будет начинаться по адресу 0x100000.
После того как компоновщик выдаст текстовую секцию, значение счетчика позиции будет 0x100000 плюс размер текстовой секции. Точно так же секции data и bss будут слиты и помещены по адресу, который задан счетчиком позиции.
GRUB и мультизагрузка
Теперь все наши файлы готовы к сборке ядра. Но поскольку мы будем загружать ядро при помощи GRUB , остается еще один шаг.
Существует стандарт для загрузки разных ядер x86 с помощью бутлоадера. Это называется «спецификация мультибута ». GRUB будет загружать только те ядра, которые ей соответствуют.
В соответствии с этой спецификацией ядро может содержать заголовок (Multiboot header) в первых 8 килобайтах. В этом заголовке должно быть прописано три поля:
- magic - содержит «волшебное» число 0x1BADB002, по которому идентифицируется заголовок;
- flags - это поле для нас не важно, можно оставить ноль;
- checksum - контрольная сумма, должна дать ноль, если прибавить ее к полям magic и flags .
Наш файл kernel.asm теперь будет выглядеть следующим образом.
kernel.asm
bits 32 section .text ;multiboot spec align 4 dd 0x1BADB002 ;magic dd 0x00 ;flags dd - (0x1BADB002 + 0x00) ;checksum global start extern kmain start: cli mov esp, stack_space call kmain hlt section .bss resb 8192 stack_space:Инструкция dd задает двойное слово размером 4 байта.
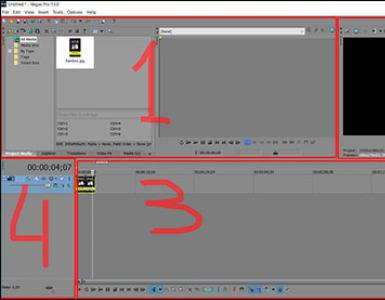
Собираем ядро
Итак, все готово для того, чтобы создать объектный файл из kernel.asm и kernel.c и слинковать их с применением нашего скрипта. Пишем в консоли:
$ nasm -f elf32 kernel.asm -o kasm.o
По этой команде ассемблер создаст файл kasm.o в формате ELF-32 bit. Теперь настал черед GCC:
$ gcc -m32 -c kernel.c -o kc.o
Параметр -c указывает на то, что файл после компиляции не нужно линковать. Мы это сделаем сами:
$ ld -m elf_i386 -T link.ld -o kernel kasm.o kc.o
Эта команда запустит компоновщик с нашим скриптом и сгенерирует исполняемый файл под названием kernel .
WARNING
Хакингом ядра лучше всего заниматься в виртуалке. Чтобы запустить ядро в QEMU вместо GRUB, используй команду qemu-system-i386 -kernel kernel .
Настраиваем GRUB и запускаем ядро
GRUB требует, чтобы название файла с ядром следовало конвенции kernel-<версия> . Так что переименовываем файл - я назову свой kernel-701 .
Теперь кладем ядро в каталог /boot . На это понадобятся привилегии суперпользователя.
В конфигурационный файл GRUB grub.cfg нужно будет добавить что-то в таком роде:
Title myKernel root (hd0,0) kernel /boot/kernel-701 ro
Не забудь убрать директиву hiddenmenu, если она прописана.
GRUB 2
Чтобы запустить созданное нами ядро в GRUB 2, который по умолчанию поставляется в новых дистрибутивах, твой конфиг должен выглядеть следующим образом:
Menuentry "kernel 701" { set root="hd0,msdos1" multiboot /boot/kernel-701 ro }
Благодарю Рубена Лагуану за это дополнение.
Перезагружай компьютер, и ты должен будешь увидеть свое ядро в списке! А выбрав его, ты увидишь ту самую строку.

Это и есть твое ядро!
Пишем ядро с поддержкой клавиатуры и экрана
Мы закончили работу над минимальным ядром, которое загружается через GRUB, работает в защищенном режиме и выводит на экран одну строку. Настала пора расширить его и добавить драйвер клавиатуры, который будет читать символы с клавиатуры и выводить их на экран.
Мы будем общаться с устройствами ввода-вывода через порты ввода-вывода. По сути, они просто адреса на шине ввода-вывода. Для операций чтения и записи в них существуют специальные процессорные инструкции.
Работа с портами: чтение и вывод
read_port: mov edx, in al, dx ret write_port: mov edx, mov al, out dx, al retДоступ к портам ввода-вывода осуществляется при помощи инструкций in и out , входящих в набор x86.
В read_port номер порта передается в качестве аргумента. Когда компилятор вызывает функцию, он кладет все аргументы в стек. Аргумент копируется в регистр edx при помощи указателя на стек. Регистр dx - это нижние 16 бит регистра edx . Инструкция in здесь читает порт, номер которого задан в dx , и кладет результат в al . Регистр al - это нижние 8 бит регистра eax . Возможно, ты помнишь из институтского курса, что значения, возвращаемые функциями, передаются через регистр eax . Таким образом, read_port позволяет нам читать из портов ввода-вывода.
Функция write_port работает схожим образом. Мы принимаем два аргумента: номер порта и данные, которые будут записаны. Инструкция out пишет данные в порт.
Прерывания
Теперь, прежде чем мы вернемся к написанию драйвера, нам нужно понять, как процессор узнает, что какое-то из устройств выполнило операцию.
Самое простое решение - это опрашивать устройства - непрерывно по кругу проверять их статус. Это по очевидным причинам неэффективно и непрактично. Поэтому здесь в игру вступают прерывания. Прерывание - это сигнал, посылаемый процессору устройством или программой, который означает, что произошло событие. Используя прерывания, мы можем избежать необходимости опрашивать устройства и будем реагировать только на интересующие нас события.
За прерывания в архитектуре x86 отвечает чип под названием Programmable Interrupt Controller (PIC). Он обрабатывает хардверные прерывания и направляет и превращает их в соответствующие системные прерывания.
Когда пользователь что-то делает с устройством, чипу PIC отправляется импульс, называемый запросом на прерывание (Interrupt Request, IRQ). PIC переводит полученное прерывание в системное прерывание и отправляет процессору сообщение о том, что пора остановить то, что он делает. Дальнейшая обработка прерываний - это задача ядра.
Без PIC нам бы пришлось опрашивать все устройства, присутствующие в системе, чтобы посмотреть, не произошло ли событие с участием какого-то из них.
Давай разберем, как это работает в случае с клавиатурой. Клавиатура висит на портах 0x60 и 0x64. Порт 0x60 отдает данные (когда нажата какая-то кнопка), а порт 0x64 передает статус. Однако нам нужно знать, когда конкретно читать эти порты.
Прерывания здесь приходятся как нельзя более кстати. Когда кнопка нажата, клавиатура отправляет PIC сигнал по линии прерываний IRQ1. PIС хранит значение offset , сохраненное во время его инициализации. Он добавляет номер входной линии к этому отступу, чтобы сформировать вектор прерывания. Затем процессор ищет структуру данных, называемую «таблица векторов прерываний» (Interrupt Descriptor Table, IDT), чтобы дать функции - обработчику прерывания адрес, соответствующий его номеру.
Затем код по этому адресу исполняется и обрабатывает прерывание.
Задаем IDT
struct IDT_entry{ unsigned short int offset_lowerbits; unsigned short int selector; unsigned char zero; unsigned char type_attr; unsigned short int offset_higherbits; }; struct IDT_entry IDT; void idt_init(void) { unsigned long keyboard_address; unsigned long idt_address; unsigned long idt_ptr; keyboard_address = (unsigned long)keyboard_handler; IDT.offset_lowerbits = keyboard_address & 0xffff; IDT.selector = 0x08; /* KERNEL_CODE_SEGMENT_OFFSET */ IDT.zero = 0; IDT.type_attr = 0x8e; /* INTERRUPT_GATE */ IDT.offset_higherbits = (keyboard_address & 0xffff0000) >> 16; write_port(0x20 , 0x11); write_port(0xA0 , 0x11); write_port(0x21 , 0x20); write_port(0xA1 , 0x28); write_port(0x21 , 0x00); write_port(0xA1 , 0x00); write_port(0x21 , 0x01); write_port(0xA1 , 0x01); write_port(0x21 , 0xff); write_port(0xA1 , 0xff); idt_address = (unsigned long)IDT ; idt_ptr = (sizeof (struct IDT_entry) * IDT_SIZE) + ((idt_address & 0xffff) << 16); idt_ptr = idt_address >> 16 ; load_idt(idt_ptr); }IDT - это массив, объединяющий структуры IDT_entry. Мы еще обсудим привязку клавиатурного прерывания к обработчику, а сейчас посмотрим, как работает PIC.
Современные системы x86 имеют два чипа PIC, у каждого восемь входных линий. Будем называть их PIC1 и PIC2. PIC1 получает от IRQ0 до IRQ7, а PIC2 - от IRQ8 до IRQ15. PIC1 использует порт 0x20 для команд и 0x21 для данных, а PIC2 - порт 0xA0 для команд и 0xA1 для данных.
Оба PIC инициализируются восьмибитными словами, которые называются «командные слова инициализации» (Initialization command words, ICW).
В защищенном режиме обоим PIC первым делом нужно отдать команду инициализации ICW1 (0x11). Она сообщает PIC, что нужно ждать еще трех инициализационных слов, которые придут на порт данных.
Эти команды передадут PIC:
- вектор отступа (ICW2),
- какие между PIC отношения master/slave (ICW3),
- дополнительную информацию об окружении (ICW4).
Вторая команда инициализации (ICW2) тоже шлется на вход каждого PIC. Она назначает offset , то есть значение, к которому мы добавляем номер линии, чтобы получить номер прерывания.
PIC разрешают каскадное перенаправление их выводов на вводы друг друга. Это делается при помощи ICW3, и каждый бит представляет каскадный статус для соответствующего IRQ. Сейчас мы не будем использовать каскадное перенаправление и выставим нули.
ICW4 задает дополнительные параметры окружения. Нам нужно определить только нижний бит, чтобы PIC знали, что мы работаем в режиме 80×86.
Та-дам! Теперь PIC проинициализированы.
У каждого PIC есть внутренний восьмибитный регистр, который называется «регистр масок прерываний» (Interrupt Mask Register, IMR). В нем хранится битовая карта линий IRQ, которые идут в PIC. Если бит задан, PIC игнорирует запрос. Это значит, что мы можем включить или выключить определенную линию IRQ, выставив соответствующее значение в 0 или 1.
Чтение из порта данных возвращает значение в регистре IMR, а запись - меняет регистр. В нашем коде после инициализации PIC мы выставляем все биты в единицу, чем деактивируем все линии IRQ. Позднее мы активируем линии, которые соответствуют клавиатурным прерываниям. Но для начала все же выключим!
Если линии IRQ работают, наши PIC могут получать сигналы по IRQ и преобразовывать их в номер прерывания, добавляя офсет. Нам же нужно заполнить IDT таким образом, чтобы номер прерывания, пришедшего с клавиатуры, соответствовал адресу функции-обработчика, которую мы напишем.
На какой номер прерывания нам нужно завязать в IDT обработчик клавиатуры?
Клавиатура использует IRQ1. Это входная линия 1, ее обрабатывает PIC1. Мы проинициализировали PIC1 с офсетом 0x20 (см. ICW2). Чтобы получить номер прерывания, нужно сложить 1 и 0x20, получится 0x21. Значит, адрес обработчика клавиатуры будет завязан в IDT на прерывание 0x21.
Задача сводится к тому, чтобы заполнить IDT для прерывания 0x21. Мы замапим это прерывание на функцию keyboard_handler , которую напишем в ассемблерном файле.
Каждая запись в IDT состоит из 64 бит. В записи, соответствующей прерыванию, мы не сохраняем адрес функции-обработчика целиком. Вместо этого мы разбиваем его на две части по 16 бит. Нижние биты сохраняются в первых 16 битах записи в IDT, а старшие 16 бит - в последних 16 битах записи. Все это сделано для совместимости с 286-ми процессорами. Как видишь, Intel выделывает такие номера на регулярной основе и во многих-многих местах!
В записи IDT нам осталось прописать тип, обозначив таким образом, что все это делается, чтобы отловить прерывание. Еще нам нужно задать офсет сегмента кода ядра. GRUB задает GDT за нас. Каждая запись GDT имеет длину 8 байт, где дескриптор кода ядра - это второй сегмент, так что его офсет составит 0x08 (подробности не влезут в эту статью). Гейт прерывания представлен как 0x8e. Оставшиеся в середине 8 бит заполняем нулями. Таким образом, мы заполним запись IDT, которая соответствует клавиатурному прерыванию.
Когда с маппингом IDT будет покончено, нам надо будет сообщить процессору, где находится IDT. Для этого существует ассемблерная инструкция lidt, она принимает один операнд. Им служит указатель на дескриптор структуры, которая описывает IDT.
С дескриптором никаких сложностей. Он содержит размер IDT в байтах и его адрес. Я использовал массив, чтобы вышло компактнее. Точно так же можно заполнить дескриптор при помощи структуры.
В переменной idr_ptr у нас есть указатель, который мы передаем инструкции lidt в функции load_idt() .
Load_idt: mov edx, lidt sti ret
Дополнительно функция load_idt() возвращает прерывание при использовании инструкции sti .
Заполнив и загрузив IDT, мы можем обратиться к IRQ клавиатуры, используя маску прерывания, о которой мы говорили ранее.
Void kb_init(void) { write_port(0x21 , 0xFD); }
0xFD - это 11111101 - включаем только IRQ1 (клавиатуру).
Функция - обработчик прерывания клавиатуры
Итак, мы успешно привязали прерывания клавиатуры к функции keyboard_handler , создав запись IDT для прерывания 0x21. Эта функция будет вызываться каждый раз, когда ты нажимаешь на какую-нибудь кнопку.
Keyboard_handler: call keyboard_handler_main iretd
Эта функция вызывает другую функцию, написанную на C, и возвращает управление при помощи инструкций класса iret. Мы могли бы тут написать весь наш обработчик, но на C кодить значительно легче, так что перекатываемся туда. Инструкции iret/iretd нужно использовать вместо ret , когда управление возвращается из функции, обрабатывающей прерывание, в программу, выполнение которой было им прервано. Этот класс инструкций поднимает флаговый регистр, который попадает в стек при вызове прерывания.
Void keyboard_handler_main(void) { unsigned char status; char keycode; /* Пишем EOI */ write_port(0x20, 0x20); status = read_port(KEYBOARD_STATUS_PORT); /* Нижний бит статуса будет выставлен, если буфер не пуст */ if (status & 0x01) { keycode = read_port(KEYBOARD_DATA_PORT); if(keycode < 0) return; vidptr = keyboard_map; vidptr = 0x07; } }
Здесь мы сначала даем сигнал EOI (End Of Interrupt, окончание обработки прерывания), записав его в командный порт PIC. Только после этого PIC разрешит дальнейшие запросы на прерывание. Нам нужно читать два порта: порт данных 0x60 и порт команд (он же status port) 0x64.
Первым делом читаем порт 0x64, чтобы получить статус. Если нижний бит статуса - это ноль, значит, буфер пуст и данных для чтения нет. В других случаях мы можем читать порт данных 0x60. Он будет выдавать нам код нажатой клавиши. Каждый код соответствует одной кнопке. Мы используем простой массив символов, заданный в файле keyboard_map.h , чтобы привязать коды к соответствующим символам. Затем символ выводится на экран при помощи той же техники, что мы применяли в первой версии ядра.
Чтобы не усложнять код, я здесь обрабатываю только строчные буквы от a до z и цифры от 0 до 9. Ты с легкостью можешь добавить спецсимволы, Alt, Shift и Caps Lock. Узнать, что клавиша была нажата или отпущена, можно из вывода командного порта и выполнять соответствующее действие. Точно так же можешь привязать любые сочетания клавиш к специальным функциям вроде выключения.
Теперь ты можешь собрать ядро, запустить его на реальной машине или на эмуляторе (QEMU) так же, как и в первой части.