Сложные SQL запросы. Вложенные запросы, объединения, представления
Вложенный запрос относится к специальным объектам в программе 1С. К его функционалу прибегают, если требуется сформировать и выполнить специальные виды запросов к таблицам базы данных (БД) в программе. Для получения результата по запросу сначала необходимо корректное составление текста запроса, который будет аккумулировать актуальную информацию об источниках для получения данных. Это могут быть таблицы, специальные поля, уникальные группировки.
Современный язык запросов для программы 1С
Вложенные запросы пишутся с применением языка, который имеет свои особенности и в тоже время похож на другие специальные языки SQL, к примеру, по своему синтаксису. Главные отличительные черты языка запросов в 1С такие:
- Разыменование ссылочных полей;
- Возможности нетипичных запросов;
- Упорядочивание по примитивным типам;
- Использование конструкции «Представление»;
- Выборка данных по шаблону;
- Совместное использование группировок и итогов;
- Конструкция с условием «Где».
Есть и другие отличительные особенности языка запросов в 1С, которые позволяют ему быть эффективным.
Что нужно знать о вложенных запросах и языке запросов?
Профессиональное изучение конструкции языка запроса позволяет не только понять, для чего предназначен язык запросов , но и научится представлять совокупность объектов базы в формате 2-х мерных таблиц, обрабатывать консоль запросов, создавать файлы для хранения списков запросов, познакомиться со специфическими полями таблиц, имеющих ссылочный тип. И всё это будут только начальные знания о системе вложенных запросов в 1С. Важно освоить и групповые операции, относящиеся к языку запросов, изучить, как делать корректную выборку по нескольким источникам данных.
Пример вложенного запроса
Рассмотрим один из вариантов вложенного запроса на основе объединения запросов. Предположим, есть документы по приходу и расходу, при этом одно и то же юридическое лицо выступает и как продавец, и как покупатель. Нам нужно узнать, общий долг по контрагенту. Для этого используем эффективную конструкцию «ОБЪЕДИНИТЬ ВСЕ».
Таблица «ПРИХОД»
Таблица «РАСХОД»

Сначала определяем все расходы, затем приход по юрлицам. Второй запрос ставим со знаком «-», это позволит корректно свернуть данные.
Результат действия:
Но нам нужно получить свёрнутый результат, требуется группировка по юридическому лицу.

Тогда результатом отчёта будет:
Когда речь идёт о таблицах Расхода и Прихода, к примеру, по справочнику Номенклатура, то необходимо исключить дублирование. Но сливать каждый из запросов отдельно не получится. Поэтому нужно сделать так:

В этом случае запрос помещён между скобками, его называют вложенным запросом. Это позволяет не только провести группировку актуальных для нас записей, но и исключить аналогичные элементы из двух используемых подзапросов.
Существуют определённые требования, которых необходимо придерживаться, выполняя объединение двух запросов. Прежде всего, это касается количества полей. Необходимо, чтобы их число было идентичным. К примеру, если бы в таблице данных «Расход» была указана Скидка, а в данных по Приходу такого элемента не было бы, то следует прибегнуть к следующей конструкции:

В дальнейшем нужно будет скорректировать величину суммы на скидку и выполнить необходимую группировку.
Вторым непременным условием является порядок. Дело в том, что процедура объединения по полям происходит в чётком соответствии с их порядком, то есть тем, как они обозначены в каждой последовательной секции. Для изменения порядка применим такую конструкцию:

Кстати, при применении конструкции Объединения следует отличать её от понятия соединения нескольких запросов. Объединение даёт возможность вертикального соединения результатов выборки, поочерёдно берутся данные из первого, потом уже переходят ко второму. Именно так получаются данные в результате конструкции объединения информации из двух таблиц.
В прошлом уроке мы столкнулись с одним неудобством. Когда мы хотели узнать, кто создал тему "велосипеды", и делали соответствующий запрос:
Вместо имени автора, мы получали его идентификатор. Это и понятно, ведь мы делали запрос к одной таблице - Темы, а имена авторов тем хранятся в другой таблице - Пользователи. Поэтому, узнав идентификатор автора темы, нам надо сделать еще один запрос - к таблице Пользователи, чтобы узнать его имя:

В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос). Итак, чтобы узнать, кто создал тему "велосипеды", мы сделаем следующий запрос:

То есть, после ключевого слова WHERE , в условие мы записываем еще один запрос. MySQL сначала обрабатывает подзапрос, возвращает id_author=2, и это значение передается в предложение WHERE внешнего запроса.
В одном запросе может быть несколько подзапросов, синтаксис у такого запроса следующий: Обратите внимание, что подзапросы могут выбирать только один столбец, значения которого они будут возвращать внешнему запросу. Попытка выбрать несколько столбцов приведет к ошибке.
Давайте для закрепления составим еще один запрос, узнаем, какие сообщения на форуме оставлял автор темы "велосипеды":
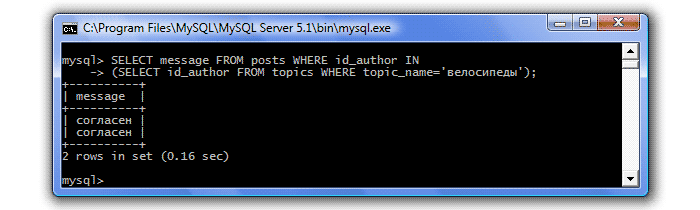
Теперь усложним задачу, узнаем, в каких темах оставлял сообщения автор темы "велосипеды":

Давайте разберемся, как это работает.
- Сначала MySQL выполнит самый глубокий запрос:
- Полученный результат (id_author=2) передаст во внешний запрос, который примет вид:
- Полученный результат (id_topic:4,1) передаст во внешний запрос, который примет вид:
- И выдаст окончательный результат (topic_name: о рыбалке, о рыбалке). Т.е. автор темы "велосипеды" оставлял сообщения в теме "О рыбалке", созданной Сергеем (id=1) и в теме "О рыбалке", созданной Светой (id=4).
- Не рекомендуется создавать запросы со степенью вложения больше трех. Это приводит к увеличению времени выполнения и к сложности восприятия кода.
- Приведенный синтаксис вложенных запросов, скорее наиболее употребительный, но вовсе не единственный. Например,
мы могли бы вместо запроса
написать
Т.е. мы можем использовать любые операторы, используемые с ключевым словом WHERE (их мы изучали в прошлом уроке).
Подзапросы
Язык SQL разрешает использовать в других операторах языка DML подзапросы , которые являются внутренними запросами, определяемыми оператором SELECT .
Подзапрос - очень мощное средство языка SQL. Он позволяет строить сложные иерархии запросов, многократно выполняемые в процессе построения результирующего набора или выполнения одного из операторов изменения данных (DELETE , INSERT , UPDATE ).
Условно подзапросы иногда подразделяют на три типа, каждый из которых является сужением предыдущего:
- табличный подзапрос , возвращающий набор строк и столбцов;
- подзапрос строки , возвращающий только одну строку, но, возможно, несколько столбцов (такие подзапросы часто используются во встроенном SQL);
- скалярный подзапрос , возвращающий значение одного столбца в одной строке.
Подзапрос позволяет решать следующие задачи:
- определять набор строк, добавляемый в таблицу на одно выполнение оператора INSERT ;
- определять данные, включаемые в представление, создаваемое оператором CREATE VIEW ;
- определять значения, модифицируемые оператором UPDATE ;
- указывать одно или несколько значений во фразах WHERE и HAVING оператора SELECT ;
- определять во фразе FROM таблицу как результат выполнения подзапроса ;
- применять коррелированные подзапросы . Подзапрос называется коррелированным, если запрос, содержащийся в предикате, имеет ссылку на значение из таблицы (внешней к данному запросу), которая проверяется посредством данного предиката.
Hекоторые СУБД (например, СУБД Oracle) позволяют на основе подзапроса создавать новые таблицы с помощью оператора CREATE TABLE .
Простым примером использования подзапроса может служить следующий оператор:
В данном операторе подзапрос всегда должен возвращать единственное значение, которое будет проверяться в предикате. Если подзапрос вернет более одного значения, то СУБД выдаст сообщение об ошибке выполнения SQL-оператора.
В случае если подзапрос не выберет ни одной строки, то предикат будет равен UNKNOWN , что большинством СУБД интерпретируется как FALSE .
Стандарт определяет запись предиката в форме "значение оператор подзапрос ". Однако некоторые СУБД также позволяют записывать предикат в форме, указывающей подзапрос слева от оператора сравнения.
Например:
Очень часто с подзапросами используются агрегирующие функции, предоставляющие возможность сформулировать условие типа "больше, чем среднее по группе".
Например:
Если результатом подзапроса становится группа строк (это случается всегда, когда условие не гарантирует уникальности значения проверяемого предикатом внутреннего запроса), то следует использовать оператор IN , осуществляющий выбор одного значения из указываемого множества.
Например:
В этом случае предикат принимает значение TRUE , если хотя бы одно из значений, возвращаемых подзапросом , удовлетворяет условию.
Однако применение оператора IN имеет и некоторые смысловые недостатки: в запросе четко не определяется, сколько строк должны быть результатом выполнения запроса. При построении отношений для реальной модели данных это может приводить к некоторой неоднозначности и зависимости от самих данных. В противном случае, если модель данных предполагает в качестве постоянного результата подзапроса наличие только одной строки и, соответственно, использует оператор сравнения = , а структура данных позволяет ввод значений, когда в результате подзапроса будет более одной строки, то при использовании такого SQL-оператора в какой-то момент времени может проявиться ошибка.
Если в запросе участвуют более двух таблиц, то для большей наглядности имена полей иногда квалифицируют именами таблиц, указывая их через точку. Стандарт позволяет не квалифицировать имя поля именем таблицы в том случае, если не возникает неоднозначности (поле сначала ищется в таблице, указанной фразой FROM текущего запроса, затем внешнего запроса и т.д.).
Очень часто вместо записи оператора SELECT с использованием подзапроса можно применять соединения. Однако на практике большинство СУБД подзапросы выполняют более эффективно. Тем не менее, при проектировании комплекса программ с критичными требованиями по быстродействию, разработчик должен проанализировать план выполнения SQL-оператора для конкретной СУБД.
Наиболее продвинутые СУБД, такие как Oracle, предоставляют ряд SQL-операторов, позволяющих оценить производительность выполнения конкретного оператора языка SQL, а также определить уровень оптимизации, применяемый для данного оператора.
Подзапрос может быть указан как в предикате, определяемом фразой WHERE , так и в предикате по группам, определяемом фразой HAVING .
Например:
Коррелированные подзапросы
В операторе SELECT из внутреннего подзапроса можно ссылаться на столбцы внешнего запроса, указанного во фразе SELECT . Такой подзапрос выполняется для каждой строки таблицы, определяя условие ее вхождения в формируемый результирующий набор.
Например:
В данном случае для каждой строки таблицы tbl1 будет проверяться условие, что значение поля f2 совпадает со значением строки таблицы tbl2 , где значение поля f3 равно значению поля f3 внешней таблицы (tbl1 ). Это простейший пример коррелированного подзапроса .
Очень часто требуется, чтобы подзапрос использовал те же данные, что и внешняя таблица. В этом случае обязательно применение алиасов.
Например:
В случае коррелированного подзапроса во фразе HAVING можно использовать только агрегирующие функции, так как каждый раз на момент выполнения подзапроса в качестве проверяемой строки, к значениям которой имеет доступ подзапрос , выступает результат группирования строк на основе агрегирующих функций основного запроса.
Например:
Построение предиката для подзапроса, возвращающего несколько строк
Если в предикате надо сравнить значение с некоторым множеством, то, как было показано выше, можно использовать оператор IN .
Для того чтобы проверить, существуют ли строки, удовлетворяющие конкретному условию подзапроса , применяется оператор EXISTS .
Например:
Этот запрос будет формировать не пустой результирующий набор только в том случае, если в какое-либо значение столбца f4 таблицы была занесена дата, например: "10/11/2003".
Преимущество применения оператора EXISTS с результатами подзапроса состоит в том, что подзапрос может возвращать как множество строк, так и множество столбцов.
При коррелированном подзапросе оператор EXISTS будет вычисляться каждый раз для каждой строки внешнего запроса.
В стандарте SQL-92 не предусмотрено использование в подзапросах , к которым применяется оператор EXISTS агрегирующих функций. Однако некоторые СУБД позволяют такой вид подзапросов .
Для использования результата подзапроса в предикате также применяются операторы ANY и ALL , которые были подробно рассмотрены в предыдущих лекциях.
Приведем пример использования оператора ANY :
Данный оператор определяет, что в результирующий набор будут включены все строки, значение столбца f3 которых присутствует в таблице tbl2 .
Применение подзапросов в операторах изменения данных
К операторам языка DML, кроме оператора SELECT , относятся операторы, позволяющие изменять данные в таблицах. Это оператор INSERT , выполняющий добавление одной или нескольких строк в таблицу, оператор DELETE , удаляющий из таблицы одну или несколько строк, и оператор UPDATE , изменяющий значения столбцов таблицы.
Оператор INSERT
Оператор INSERT
INSERT INTO table_name [ (field .,:) ] { VALUES (value .,:) } | subquery | {DEFAULT VALUES};
Оператор INSERT может добавлять в таблицу как одну, так и несколько строк. Список полей (field .,:) указывает имена полей и порядок занесения в них значений из списка значений, определяемого фразой VALUES , или как результат выполнения подзапроса .
Список, определяемый фразой VALUES , называется конструктором значений таблицы и указывается в круглых скобках через запятую.
Если список полей (field .,:) опущен, то порядок занесения значений будет соответствовать порядку столбцов, указанному в операторе CREATE TABLE при создании данной таблицы.
Если для столбцов, на которые установлено ограничение NOT NULL , не указано добавляемых данных, то СУБД инициирует ошибку выполнения SQL-оператора.
Следующий оператор INSERT демонстрирует копирование строк таблицы tbl2 , выполняемое на основе подзапроса :
INSERT INTO tbl1(f1,f2,f3) (SELECT f1,f2,f3 FROM tbl2);
Очевидно, что количество полей, указываемое списком полей, и типы данных этих полей должны совпадать с количеством полей и их типами данных в конструкторе значений таблицы или в результирующем наборе, формируемом подзапросом .
Оператор DELETE
Оператор DELETE в стандарте SQL-92 имеет следующее формальное описание:
Оператор DELETE используется для удаления из таблицы строк, указанных условием во фразе WHERE (поисковое удаление, searched deletion) или WHERE CURRENT OF (позиционное удаление, positioned deletion).
Позиционное удаление, определяемое фразой WHERE CURRENT OF , удаляя строки из курсора, соответственно удаляет их и из той таблицы базы данных, на базе которой был построен этот курсор.
Если оператор DELETE применяется к какому-либо представлению, то данные удаляются также из созданной на основе последнего таблицы базы данных.
Никогда нельзя забывать, что если фраза WHERE будет отсутствовать или предикат во фразе WHERE будет всегда принимать значение TRUE , то оператор DELETE удалит из таблицы все строки.
Оператор UPDATE
Оператор UPDATE в стандарте SQL-92 имеет следующее формальное описание:
Оператор UPDATE применяется для внесения изменений в данные таблиц.
Выражение expr , используемое для вычисления значения столбца, может быть как простым выражением, так и подзапросом , возвращающим единственное значение. В выражении можно ссылаться на старое значение изменяемого столбца и других столбцов текущей записи.
При вычислении значений столбцов можно применять условное выражение CASE и выражение CAST для приведения типов.
Например:
Условное выражение CASE
Условное выражение CASE позволяет выбрать одно из нескольких значений на основании указываемого условия.
Условное выражение CASE имеет следующее формальное описание:
{ CASE { expr WHEN expr THEN { expr | NULL }} | { WHEN expr THEN { expr | NULL }} [ ELSE { expr | NULL } ] END} | { NULLIF {expr1,expr2) } | {COALESCE (expr .,:) }
Условное выражение CASE может быть записано, соответственно, в четырех формах:
- CASE
с выражениями. Например:
SELECT f1, CASE f3 WHEN "abc" THEN "1_abc" END FROM tbl1;
- CASE
с предикатами. Например:
SELECT f1, CASE WHEN f3= "abc" THEN "1_abc" ELSE f3 END FROM tbl1;
- NULLIF - если выражения, указанные в скобках, не совпадают, то выбирается первое из этих значений, в противном случае устанавливается значение NULL . Например:
- COALESCE
- выбирается первое значение в списке, не равное NULL
. Например:
INSERT INTO tbl1(f1,f2) VALUES (1+ COALESCE(SELECT MAX(f1) FROM tbl1, 0), 100);
Для успешного выполнения оператора UPDATE требуется ряд условий, включающий следующие:
- наличие соответствующих привилегий;
- для представления требуется определение его как изменяемого;
- при изменении представлений применяются ограничения WITH CHECK OPTION или WITH CASCADED CHECK OPTION , установленные при создании этого представления;
- в транзакциях "только чтение" изменение доступно только для временных таблиц;
- выражения, используемые для определения значений, не могут содержать подзапросы с агрегирующими функциями;
- для обновляемого курсора, указанного фразой FOR UPDATE , каждый изменяемый столбец также должен быть определен как FOR UPDATE ;
- в курсоре с фразой ORDER BY нельзя выполнять изменение столбцов, указанных в этой фразе.
Вложенные запросы – это запросы, вызываемые другим, внешним, запросом. Они всегда заключаются в круглые скобки и им обязательно должен присваиваться псевдоним. Некоторые считают вложенный запрос аналогом временных таблиц, однако эти два инструмента имеют ряд отличий, которые мы рассмотрим в данной статье.
Вложенный запрос видит только себя, он не видит внешний запрос. Это значит, что нельзя, например, установить во вложенном запросе условие по значению поля внешнего запроса.
Большинство представленных запросов не имеют какой-либо ценности и могли бы быть выполнены проще. Они приведены только для иллюстрации механизма вложенных запросов.
Вложенные запросы могут использоваться в конструкции ИЗ:
Запрос.
Текст=
"ВЫБРАТЬ
ВложенныйЗапрос.Поле1,
ВложенныйЗапрос.Поле2
ИЗ
(ВЫБРАТЬ
Таблица1.Поле1,
Таблица1.Поле2
ИЗ ТаблицаДанных КАК Таблица1) КАК ВложенныйЗапрос"
;
В том числе в соединениях:
Запрос.
Текст=
"ВЫБРАТЬ
ВложенныйЗапрос.Наименование,
ИЗ
(ВЫБРАТЬ
Контрагенты.Ссылка КАК Ссылка,
Контрагенты.Наименование КАК Наименование
ИЗ
Справочник.Контрагенты КАК Контрагенты) КАК ВложенныйЗапрос
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ЧерныйСписок.СрезПоследних КАК ЧерныйСписокСрезПоследних
ПО ВложенныйЗапрос.Ссылка = ЧерныйСписокСрезПоследних.Котрагент"
;
И в условиях запроса со сравнением В или В ИЕРАРХИИ:
Запрос.
Текст=
"ВЫБРАТЬ
ЧерныйСписокСрезПоследних.Состояние
ИЗ
РегистрСведений.ЧерныйСписок.СрезПоследних КАК ЧерныйСписокСрезПоследних
ГДЕ
ЧерныйСписокСрезПоследних.Котрагент В
(ВЫБРАТЬ ПЕРВЫЕ 10
Контрагенты.Ссылка
ИЗ
Справочник.Контрагенты КАК Контрагенты)"
;
При этом количество выбираемых полей вложенного запроса должно соответствовать количеству операндов в левой части выражения В или В ИЕРАРХИИ.
Существует мнение, что вложенные запросы в сложных конструкциях выполняются платформой 1С нерационально, требуют бОльших ресурсов и времени, нежели те же самые запросы, выполненные иначе, без использования вложенных запросов. Однако в ряде случаев, обойтись без вложенных запросов невозможно.
Вместе с тем, обычно эффективнее работает один большой запрос с вложенными, чем последовательность запросов из модуля.
Практически всегда альтернативой вложенному запросу является использование временных таблиц. Этот инструмент имеет ряд преимуществ:
- Запрос становится более структурированным, его легче читать.
- Результат, загруженный во временную таблицу можно использовать несколько раз, и при этом нет необходимости заново выполнять запрос, чтобы этот результат получить. А вложенный запрос будет каждый раз выполняться заново, излишне загружая ресурсы системы.
Подведем итог: вложенные запросы лучше всего применять в достаточно простых конструкциях, при этом использовать их стоит только тогда, когда по-другому задачу не решить; в сложных запросах лучше использовать временные таблицы.