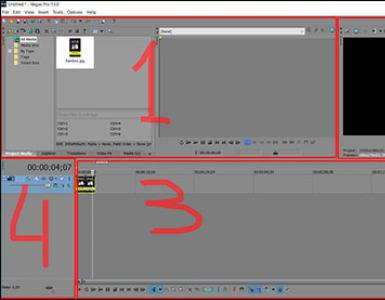
Прерывания обработка прерываний. Системы прерываний
Нейросети создают и обучают в основном на языке Python. Поэтому очень важно иметь базовые представления о том, как писать на нем программы. В этой статье я кратко и понятно расскажу об основных понятиях этого языка: переменных, функциях, классах и модулях.
Материал рассчитан на людей, не знакомых с языками программирования.
Для начала Python надо установить. Затем нужно поставить удобную среду для написания программ на Python. Этим двум шагам посвящена на портале.
Если все установлено и настроено, можно начинать.
Переменные
Переменная - ключевое понятие в любом языке программирования (и не только в них). Проще всего представить переменную в виде коробки с ярлыком. В этой коробке хранится что-то (число, матрица, объект, …) представляющее для нас ценность.
Например, мы хотим создать переменную x , которая должна хранить значение 10. В Python код создания этой переменной будет выглядеть так:

Слева мы объявляем переменную с именем x . Это равносильно тому, что мы приклеили на коробку именной ярлык. Далее идет знак равенства и число 10. Знак равенства здесь играет необычную роль. Он не означает, что «x равно 10». Равенство в данном случае кладет число 10 в коробку. Если говорить более корректно, то мы присваиваем переменной x число 10.
Теперь, в коде ниже мы можем обращаться к этой переменной, также выполнять с ней различные действия.
Можно просто вывести значение этой переменной на экран:
X=10 print(x)
Надпись print(x) представляет собой вызов функции. Их мы будем рассматривать далее. Сейчас важно то, что эта функция выводит в консоль то, что расположено между скобками. Между скобками у нас стоит x . Ранее мы присвоили x значение 10. Именно 10 и выводится в консоли, если вы выполните программу выше.
С переменными, которые хранят числа, можно выполнять различные простейшие действия: складывать, вычитать, умножать, делить и возводить в степень.
X = 2 y = 3 # Сложение z = x + y print(z) # 5 # Разность z = x - y print(z) # -1 # Произведение z = x * y print(z) # 6 # Деление z = x / y print(z) # 0.66666... # Возведение в степень z = x ** y print(z) # 8
В коде выше мы вначале создаем две переменные, содержащие 2 и 3. Затем создаем переменную z , которая хранит результат операции с x и y и выводит результаты в консоль. На этом примере хорошо видно, что переменная может менять свое значение в ходе выполнения программы. Так, наша переменная z меняет свое значение аж 5 раз.
Функции
Иногда возникает необходимость много раз выполнять одни и те же действия. Например, в нашем проекте нужно часто выводить 5 строчек текста.
«Это очень важный текст!»
«Этот текст нильзя ни прочитать»
«Ошибка в верхней строчке допущена специально»
«Привет и пока»
«Конец»
Наш код будет выглядеть так:
X = 10 y = x + 8 - 2 print("Это очень важный текст!") print("Этот текст нильзя не прочитать") print("Ошибка в верхней строчке допущена специально") print("Привет и пока") print("Конец") z = x + y print("Это очень важный текст!") print("Этот текст нильзя не прочитать") print("Ошибка в верхней строчке допущена специально") print("Привет и пока") print("Конец") test = z print("Это очень важный текст!") print("Этот текст нильзя не прочитать") print("Ошибка в верхней строчке допущена специально") print("Привет и пока") print("Конец")
Выглядит все это очень избыточно и неудобно. Кроме того, во второй строчке допущена ошибка. Ее можно исправить, но исправлять придется сразу в трех местах. А если у нас в проекте эти пять строчек вызываются 1000 раз? И все в разных местах и файлах?
Специально для случаев, когда необходимо часто выполнять одни и те же команды, в языках программирования можно создавать функции.
Функция - отдельный блок кода, который можно вызывать по имени.
Задается функция с помощью ключевого слова def . Далее следует название функции, затем скобки и двоеточие. Дальше с отступом надо перечислить действия, которые будут выполнены при вызове функции.
Def print_5_lines(): print("Это очень важный текст!") print("Этот текст нильзя не прочитать") print("Ошибка в верхней строчке допущена специально") print("Привет и пока") print("Конец")
Теперь мы определили функцию print_5_lines() . Теперь, если в нашем проекте нам в очередной раз надо вставить пять строчек, то мы просто вызываем нашу функцию. Она автоматически выполнит все действия.
# Определяем функцию def print_5_lines(): print("Это очень важный текст!") print("Этот текст нильзя не прочитать") print("Ошибка в верхней строчке допущена специально") print("Привет и пока") print("Конец") # Код нашего проекта x = 10 y = x + 8 - 2 print_5_lines() z = x + y print_5_lines() test = z print_5_lines()
Удобно, не правда ли? Мы серьезно повысили читаемость кода. Кроме того, функции хороши еще и тем, что если вы хотите изменить какое-то из действий, то достаточно подправить саму функцию. Это изменение будет работать во всех местах, где вызывается ваша функция. То есть мы можем исправить ошибку во второй строчке выводимого текста («нильзя» > «нельзя») в теле функции. Правильный вариант автоматически будет вызываться во всех местах нашего проекта.

Функции с параметрами
Просто повторять несколько действий конечно удобно. Но это еще не все. Иногда мы хотим передать какую-ту переменную в нашу функцию. Таким образом, функция может принимать данные и использовать их в процессе выполнения команд.
Переменные, которые мы передаем в функцию, называются аргументами .
Напишем простую функцию, которая складывает два данных ей числа и возвращает результат.
Def sum(a, b): result = a + b return result
Первая строчка выглядит почти так же, как и обычные функции. Но между скобок теперь находятся две переменные. Это параметры функции. Наша функция имеет два параметра (то есть принимает две переменные).
Параметры можно использовать внутри функции как обычные переменные. На второй строчке мы создаем переменную result , которая равна сумме параметров a и b . На третьей строчке мы возвращаем значение переменной result .
Теперь, в дальнейшем коде мы можем писать что-то вроде:
New = sum(2, 3) print(new)
Мы вызываем функцию sum и по очереди передаем ей два аргумента: 2 и 3. 2 становится значением переменной a , а 3 становится значением переменной b . Наша функция возвращает значение (сумму 2 и 3), и мы используем его для создания новой переменной new .
Запомните. В коде выше числа 2 и 3 - аргументы функции sum . А в самой функции sum переменные a и b - параметры. Другими словами, переменные, которые мы передаем функции при ее вызове называются аргументами. А вот внутри функции эти переданные переменные называются параметрами. По сути, это два названия одного и того же, но путать их не стоит.
Рассмотрим еще один пример. Создадим функцию square(a) , которая принимает какое-то одно число и возводит его в квадрат:
Def square(a): return a * a
Наша функция состоит всего из одной строчки. Она сразу возвращает результат умножения параметра a на a .
Я думаю вы уже догадались, что вывод данных в консоль мы тоже производим с помощью функции. Эта функция называется print() и она выводит в консоль переданный ей аргумент: число, строку, переменную.
Массивы
Если переменную можно представлять как коробку, которая что-то хранит (не обязательно число), то массивы можно представить в виде книжных полок. Они содержат сразу несколько переменных. Вот пример массива из трех чисел и одной строки:
Array =
Вот и пример, когда переменная содержит не число, на какой-то другой объект. В данном случае, наша переменная содержит массив. Каждый элемент массива пронумерован. Попробуем вывести какой-нибудь элемент массива:
Array = print(array)
В консоли вы увидите число 89. Но почему 89, а не 1? Все дело в том, что в Python, как и во многих других языках программирования, нумерация массивов начинается с 0. Поэтому array дает нам второй элемент массива, а не первый. Для вызова первого надо было написать array .
Размер массива
Иногда бывает очень полезно получить количество элементов в массиве. Для этого можно использовать функцию len() . Она сама подсчитает количество элементов и вернет их число.
Array = print(len(array))
В консоли выведется число 4.
Условия и циклы
По умолчанию любые программы просто подряд выполняют все команды сверху вниз. Но есть ситуации, когда нам необходимо проверить какое-то условие, и в зависимости от того, правдиво оно или нет, выполнить разные действия.
Кроме того, часто возникает необходимость много раз повторить практически одинаковую последовательность команд.
В первой ситуации помогают условия, а во второй - циклы.
Условия
Условия нужны для того, чтобы выполнить два разных набора действий в зависимости от того, истинно или ложно проверяемое утверждение.

В Python условия можно записывать с помощью конструкции if: ... else: ... . Пусть у нас есть некоторая переменная x = 10 . Если x меньше 10, то мы хотим разделить x на 2. Если же x больше или равно 10, то мы хотим создать другую переменную new , которая равна сумме x и числа 100. Вот так будет выглядеть код:
X = 10 if(x < 10): x = x / 2 print(x) else: new = x + 100 print(new)
После создания переменной x мы начинаем записывать наше условие.
Начинается все с ключевого слова if (в переводе с английского «если»). В скобках мы указываем проверяемое выражение. В данном случае мы проверяем, действительно ли наша переменная x меньше 10. Если она действительно меньше 10, то мы делим ее на 2 и выводит результат в консоль.
Затем идет ключевое слово else , после которого начинается блок действий, которые будут выполнены, если выражение в скобках после if ложное.
Если она больше или равна 10, то мы создаем новую переменную new , которая равна x + 100 и тоже выводим ее в консоль.
Циклы
Циклы нужны для многократного повторения действий. Предположим, мы хотим вывести таблицу квадратов первых 10 натуральных чисел. Это можно сделать так.
Print("Квадрат 1 равен " + str(1**2)) print("Квадрат 2 равен " + str(2**2)) print("Квадрат 3 равен " + str(3**2)) print("Квадрат 4 равен " + str(4**2)) print("Квадрат 5 равен " + str(5**2)) print("Квадрат 6 равен " + str(6**2)) print("Квадрат 7 равен " + str(7**2)) print("Квадрат 8 равен " + str(8**2)) print("Квадрат 9 равен " + str(9**2)) print("Квадрат 10 равен " + str(10**2))
Пусть вас не удивляет тот факт, что мы складываем строки. «начало строки» + «конец» в Python означает просто соединение строк: «начало строкиконец». Так же и выше мы складываем строку «Квадрат x равен » и преобразованный с помощью функции str(x**2) результат возведения числа во 2 степень.
Выглядит код выше очень избыточно. А что, если нам надо вывести квадраты первых 100 чисел? Замучаемся выводить…
Именно для таких случаев и существуют циклы. Всего в Python 2 вида циклов: while и for . Разберемся с ними по очереди.
Цикл while повторяет необходимые команды до тех пор, пока остается истинным условие.
X = 1 while x <= 100: print("Квадрат числа " + str(x) + " равен " + str(x**2)) x = x + 1
Сначала мы создаем переменную и присваиваем ей число 1. Затем создаем цикл while и проверяем, меньше (или равен) ли 100 наш x . Если меньше (или равен) то мы выполняем два действия:
- Выводим квадрат x
- Увеличиваем x на 1
После второй команды программа возвращается к условию. Если условие снова истинно, то мы снова выполняем эти два действия. И так до тех пор, пока x не станет равным 101. Тогда условие вернет ложь и цикл больше не будет выполняться.
Цикл for предназначен для того, чтобы перебирать массивы. Запишем тот же пример с квадратами первой сотни натуральных чисел, но уже через цикл for .
For x in range(1,101): print("Квадрат числа " + str(x) + " равен " + str(x**2))
Разберем первую строку. Мы используем ключевое слово for для создания цикла. Далее мы указываем, что хотим повторить определенные действия для всех x в диапазоне от 1 до 100. Функция range(1,101) создает массив из 100 чисел, начиная с 1 и заканчивая 100.
Вот еще пример перебора массива с помощью цикла for:
For i in : print(i * 2)
Код выше выводит 4 цифры: 2, 20, 200 и 2000. Тут наглядно видно, как берет каждый элемент массива и выполняет набор действий. Затем берет следующий элемент и повторяет тот же набор действий. И так пока элементы в массиве не кончатся.
Классы и объекты
В реальной жизни мы оперируем не переменными или функциями, а объектами. Ручка, машина, человек, кошка, собака, самолет - объекты. Теперь начнем подробно рассматривать кошку.
Она обладает некоторыми параметрами. К ним относятся цвет шерсти, цвет глаз, ее кличка. Но это еще не все. Помимо параметров, кошка может выполнять различные действия: мурлыкать, шипеть и царапаться.
Только что мы схематически описали всех кошек в целом. Подобное описание свойств и действий какого-то объекта (например, кошки) на языке Python и называется классом. Класс - просто набор переменных и функций, которые описывают какой-то объект.
Важно понимать разницу между классом и объектом. Класс - схема , которая описывает объект. Объект - ее материальное воплощение . Класс кошки - описание ее свойств и действий. Объект кошки и есть сама реальная кошка. Может быть много разных реальных кошек - много объектов-кошек. Но класс кошки только один. Хорошей демонстрацией служит картинка ниже:

Классы
Для создания класса (схемы нашей кошки) надо написать ключевое слово class и затем указать имя этого класса:
Class Cat:
Дальше нам нужно перечислить действия этого класса (действия кошки). Действия, как вы могли уже догадаться, представляют собой функции, определенные внутри класса. Такие функции внутри класса принято называть методами.
Метод - функция, определенная внутри класса.
Словесно мы уже описали методы кошки выше: мурлыкать, шипеть, царапаться. Теперь сделаем это на языке Python.
# Класс кошки class Cat: # Мурлыкать def purr(self): print("Муррр!") # Шипеть def hiss(self): print("Кшшш!") # Царапаться def scrabble(self): print("Царап-царап!")
Вот так все просто! Мы взяли и определили три обычные функции, но только внутри класса.
Для того, чтобы разобраться с непонятным параметром self , добавим еще один метод нашей кошке. Этот метод будет разом вызывать все три уже созданных метода.
# Класс кошки class Cat: # Мурлыкать def purr(self): print("Муррр!") # Шипеть def hiss(self): print("Кшшш!") # Царапаться def scrabble(self): print("Царап-царап!") # Все вместе def all_in_one(self): self.purr() self.hiss() self.scrabble()
Как видите, обязательный для любого метода параметр self позволяет нам обращаться к методами и переменным самого класса! Без этого аргумента выполнить подобные действия мы бы не смогли.
Давайте теперь зададим свойства нашей кошки (цвет шерсти, цвет глаз, кличка). Как это сделать? В абсолютно любом классе можно определить функцию __init__() . Эта функция всегда вызывается, когда мы создаем реальный объект нашего класса.
В выделенном выше методе __init__() мы задаем переменные нашей кошки. Как мы это делаем? Сначала мы передаем в этот метод 3 аргумента, отвечающие за цвет шерсти, цвет глаз и кличку. Затем, мы используем параметр self для того, чтобы при создании объекта сразу задать нашей кошки 3 описанных выше атрибута.
Что означает эта строчка?
Self.wool_color = wool_color
В левой части мы создаем атрибут для нашей кошки с именем wool_color , а дальше мы присваиваем этому атрибуту значение, которое содержится в параметре wool_color , который мы передали в функцию __init__() . Как видите, строчка выше не отличается от обычного создания переменной. Только приставка self указывает на то, что эта переменная относится к классу Cat .
Атрибут - переменная, которая относится к какому-то классу.
Итак, мы создали готовый класс кошки. Вот его код:
# Класс кошки class Cat: # Действия, которые надо выполнять при создании объекта "Кошка" def __init__(self, wool_color, eyes_color, name): self.wool_color = wool_color self.eyes_color = eyes_color self.name = name # Мурлыкать def purr(self): print("Муррр!") # Шипеть def hiss(self): print("Кшшш!") # Царапаться def scrabble(self): print("Царап-царап!") # Все вместе def all_in_one(self): self.purr() self.hiss() self.scrabble()
Объекты
Мы создали схему кошки. Теперь давайте создадим по этой схеме реальный объект кошки:
My_cat = Cat("черный", "зеленые", "Зося")
В строке выше мы создаем переменную my_cat , а затем присваиваем ей объект класса Cat . Выглядит все этот как вызов некоторой функции Cat(...) . На самом деле так и есть. Этой записью мы вызываем метод __init__() класса Cat . Функция __init__() в нашем классе принимает 4 аргумента: сам объект класса self , который указывать не надо, а также еще 3 разных аргумента, которые затем становятся атрибутами нашей кошки.
Итак, с помощью строчки выше мы создали реальный объект кошки. Наша кошка имеет следующие атрибуты: черную шерсть, зеленые глаза и кличку Зося. Давайте выведем эти атрибуты в консоль:
Print(my_cat.wool_color) print(my_cat.eyes_color) print(my_cat.name)
То есть обратиться к атрибутам объекта мы можем, записав имя объекта, поставив точку и указав имя желаемого атрибута.
Атрибуты кошки можно менять. Например, давайте сменим кличку нашей кошки:
My_cat.name = "Нюша"
Теперь, если вы вновь выведете в консоль имя кошки, то вместо Зоси увидите Нюшу.
Напомню, что класс нашей кошки позволяет ей выполнять некоторые действия. Если мы погладим нашу Зосю/Нюшу, то она начнет мурлыкать:
My_cat.purr()
Выполнение данной команды выведет в консоль текст «Муррр!». Как видите, обращаться к методам объекта так же просто, как и обращаться к его атрибутам.
Модули
Любой файл с расширением.py является модулем. Даже тот, в котором вы отрабатываете эту статью. Зачем они нужны? Для удобства. Очень много людей создают файлы с полезными функциями и классами. Другие программисты подключают эти сторонние модули и могут использовать все определенные в них функции и классы, тем самым упрощая себе работу.
Например, вам не нужно тратить время и писать свои функции для работы с матрицами. Достаточно подключить модуль numpy и использовать его функции и классы.
На данный момент другие Python программисты написали уже свыше 110 000 разнообразных модулей. Упоминавшийся выше модуль numpy позволяет быстро и удобно работать с матрицами и многомерными массивами. Модуль math предоставляет множество методов для работы с числами: синусы, косинусы, переводы градусов в радианы и прочее и прочее…
Установка модуля
Python устанавливается вместе со стандартным набором модулей. В этот набор входит очень большое количество модулей, которые позволяют работать с математикой, web-запросами, читать и записывать файлы и выполнять другие необходимые действия.
Если вы хотите использовать модуль, который не входит в стандартный набор, то вам потребуется установить его. Для установки модуля откройте командую строку (Win + R, затем введите в появившемся поле «cmd») и введите в нее команду:
Pip install [название_модуля]
Начнется процесс установки модуля. Когда он завершится, вы можете спокойно использовать установленный модуль в своей программе.
Подключение и использование модуля
Сторонний модуль подключается очень просто. Надо написать всего одну короткую строку кода:
Import [название_модуля]
Например, для импорта модуля, позволяющего работать с математическими функциями, надо написать следующее:
Import math
Как обратиться к функции модуля? Надо написать название модуля, затем поставить точку и написать название функции/класса. Например, факториал 10 находится так:
Math.factorial(10)
То есть мы обратились к функции factorial(a) , которая определена внутри модуля math . Это удобно, ведь нам не нужно тратить время и вручную создавать функцию, которая считает факториал числа. Можно подключить модуль и сразу выполнить необходимое действие.
Некоторые из вас наверняка недавно проходили Stanford"ские курсы, в частности ai-class и ml-class . Однако, одно дело просмотреть несколько видео-лекций, поотвечать на вопросики quiz"ов и написать десяток программ в Matlab / Octave , другое дело начать применять полученные знания на практике. Дабы знания полученые от Andrew Ng не угодили в тот же тёмный угол моего мозга, где заблудились dft , Специальная теория относительности и Уравнение Эйлера Лагранжа , я решил не повторять институтских ошибок и, пока знания ещё свежи в памяти, практиковаться как можно больше.И тут как раз на наш сайтик приехал DDoS. Отбиваться от которого можно было админско-программерскими (grep / awk / etc) способами или же прибегнуть к использованию технологий машинного обучения.
Пример построения словаря и feature-vector"а
Предположим, мы обучаем нашу нейронную сеть всего на двух примерах: одном хорошем и одном плохом. Потом попробуем её активировать на тестовой записи.Запись из "плохого" лога:
0.0.0.0 - - "POST /forum/index.php HTTP/1.1" 503 107 "http://www.mozilla-europe.org/" "-"
Запись из "хорошего" лога:
0.0.0.0 - - "GET /forum/rss.php?topic=347425 HTTP/1.0" 200 1685 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; pl; rv:1.9) Gecko/2008052906 Firefox/3.0"
Получившийся словарь:
["__UA___OS_U", "__UA_EMPTY", "__REQ___METHOD_POST", "__REQ___HTTP_VER_HTTP/1.0", "__REQ___URL___NETLOC_", "__REQ___URL___PATH_/forum/rss.php", "__REQ___URL___PATH_/forum/index.php", "__REQ___URL___SCHEME_", "__REQ___HTTP_VER_HTTP/1.1", "__UA___VER_Firefox/3.0", "__REFER___NETLOC_www.mozilla-europe.org", "__UA___OS_Windows", "__UA___BASE_Mozilla/5.0", "__CODE_503", "__UA___OS_pl", "__REFER___PATH_/", "__REFER___SCHEME_http", "__NO_REFER__", "__REQ___METHOD_GET", "__UA___OS_Windows NT 5.1", "__UA___OS_rv:1.9", "__REQ___URL___QS_topic", "__UA___VER_Gecko/2008052906"]
Тестовая запись:
0.0.0.0 - - "GET /forum/viewtopic.php?t=425550 HTTP/1.1" 502 107 "-" "BTWebClient/3000(25824)"
Её feature-vector:
Заметьте, насколько "разрежен" (sparse) feature-vector - такое поведение будет наблюдаться для всех запросов.
Разделение Dataset"а
Хорошей практикой является разделение dataset "а на несколько частей. Я бил на две части в пропорции 70/30:- Training set . На нём мы обучаем нашу нейронную сеть.
- Test set . Им мы проверяем, насколько хорошо обучена наша нейронная сеть.
В дальнейшем, если придётся озадачиться выбором оптимальных констант, dataset надо будет разбить на 3 части в соотношении 60/20/20: Training set , Test set и Cross validation . Последний как раз и будет служить для выбора оптимальных параметров нейронной сети (например weightdecay).
Нейронная сеть в частности
Теперь, когда у нас на руках больше нет никаких текстовых логов, а есть только матрицы из feature-vector "ов, можно приступать к построению самой нейронной сети.Начнём с выбора структуры. Я выбрал сеть из одного скрытого слоя размером с удвоенный входной слой. Почему? Всё просто: так завещал Andrew Ng в случае, если не знаете с чего начать. Думаю, в дальнейшем с этим можно поиграться, порисовав графики обучения.
Функцией активации для скрытого слоя выбрана многострадальная сигмойда, а для выходного слоя - Softmax . Последний выбран на случай, если придётся делать
многоклассовую класиффикацию c mutually exclusive классами. Например, "хорошие" запросы отправлять на бэкенд, "плохие" - в бан на фаерволе, а "серые" - разгадывать капчу.
Нейронная сеть склонна к уходу в локальный минимум, поэтому у себя в коде я строю несколько сетей и выбираю ту, у которой наименьший Test error (Заметьте, именно ошибка на test set , а не trainig set).
Disclaimer
Я не настоящий сварщик. О Machine Learning я знаю только то, что подчерпнул из ml-class и ai-class. На питоне программировать начал относительно недавно, а код ниже был написан минут за 30 (время, как вы понимаете, поджимало) и в дальнейшем был лишь слегка подпилен напильником.Также этот код не самодостаточен. Ему всё равно нужна скриптовая обвязка. Например, если IP сделал N плохих запросов в течение X минут, то банить его на firewall"е.
Производительность
- lfu_cache. Портировал с ActiveState, дабы сильно ускорить обработку запросов-"высокочастотников". Down-side - повышенное потребление памяти.
- PyBrain, внезапно, написан на python и поэтому не очень быстр, однако, он может использовать ATLAS-based -модуль arac , если при создании сети указать Fast=True . Подробнее про это можно почитать в документации к PyBrain .
- Распараллеливание. Свою нейронную сеть я обучил на довольно "толстом" серверном Nehalem"е, однако, даже там чувствовалась ущербность однопоточного обучения. Можно поразмыслить на тему распараллеливания обучения нейронной сети. Простое решение - тренировать сразу несколько нейронных сетей параллельно и из них выбирать лучшую, но это создаст дополнительную нагрузку на память, что тоже не очень хорошо. Хотелось бы более универсальное решение. Возможно имеет смысл просто переписать всё на C, благо вся теоретическая база в ml-class"е была расжевана.
- Потребление памяти и кол-во features. Хорошей оптимизацией по памяти являлся переход со стндартных питоновских массивов на numpy"ные. Так же уменьшение размера dictionary и/или использование PCA может очень хорошо помочь, об этом чуть ниже.
На будущее
- Дополнительные поля в лог. В combined лог можно добавить ещё много всего, стоит подумать на тему, какие поля помогут в идентификации ботов. Возможно, имеет смысл учитывать первый октет IP адреса, ибо в не интернациональном web-проекте китайские пользователи вероятнее всего боты.
Прерывания в микроконтроллерах представляет собоймеханизм, который позволяет микроконтроллеру реагировать на внешние события. Этот механизм работает таким образом, что при наступлении некоторого события в процессоре возникает сигнал, заставляющий процессор прервать выполнение текущей программы, т.е. говорят, что возникло прерывание. После того как выполнение текущей программы прервано, процессор должен перейти к выполнению программной процедуры, связанной с этим событием (прерыванием) – процедуры обработки прерывания. Однако, прежде чем перейти непосредственно к процедуре обработки прерывания, процессор должен выполнить ряд предварительных действий. Прежде всего, для того чтобы в будущем он смог корректно продолжить прерванную программу, необходимо сохранить состояние процессора (счетик команд, слово состояния процессора, внутренние регистры и т.д.) на момент, предшествующий прерыванию. Т.е. другими словами, требуется сохранить состояния всех тех ресурсов,которые так или иначе могут быть изменены в процессе обработки прерывания. Далее, если в системе имеется несколько возможных источников прерываний (а обычно так и бывает), процессор должен определить источник запроса прерываний. И, наконец, затем перейти к самой процедуре прерываний, конкретной для данного прерывания. По завершению обработки прерывания процессор должен восстановить состояние ресурсов, соответствующее прерванной программе, после чего она может быть продолжена. Следует отметить, что для сохранения всех требуемых ресурсов, поиска источника прерывания и перехода к процедуре обработки прерывания процессор должен затратить вполне определенное время. Это время называется скрытым временем прерывания. Чем меньше скрытое время прерывания, тем выше скорость реакции системы на внешние события и тем выше производительность системы. Во многом это определяется системой прерывания процессора и она является одной из основных особенностей архитектуры контроллера.
Под системой прерываний мы будем понимать совокупность аппаратных и программных средств, реализующих механизм прерываний в микроконтроллере. Хотя существуют большое множество различных вариантов построения систем прерываний, тем не менее, можно выделить несколько основных способов организации систем прерываний. Они отличаются между собой объемом аппаратных средств, необходимых для реализации такой системы и соответственно имеют различное быстродействие. Рассмотрим эти варианты.
Одноуровневые прерывания
Данная система прерываний реализована таким образом, что при возникновении прерывания процессор аппаратно переходит к подпрограмме обработки прерываний, расположенной по некоторому фиксированному адресу. Чтобы упростить аппаратную часть системы прерываний, этот адрес обычно располагается либо в начале, либо в конце адресного пространства программной памяти. Поскольку для обработки ВСЕХ прерываний используется только ОДНА точка входа, то такая система прерываний получила название одноуровневой. В такой системе выявление источника прерываний путем опроса состояния флажков признаков прерываний в начале программы обработки прерываний. При обнаружении установленного флажка происходит переход к соответствующему участку процедуры. Чем больше возможных источников прерываний, тем больше времени необходимо для обнаружения источника прерывания. Такой метод обнаружения источника прерывания называется программным опросомили поллингом (polling ). Его недостатком является довольно большое время, затрачиваемое на поиск источника прерывания и, как следствие, замедленная реакция системы на внешние события. Его достоинство – простота реализации системы прерываний.
Векторные прерывания
Чтобы значительно уменьшить время реакции на внешние события, используются многоуровневые или, что то же самое, векторные прерывания. В векторных прерываниях КАЖДОМУ источнику прерывания соответствует СВОЙ, вполне определенный, адрес процедуры обработки прерывания, который принято называть вектором прерывания.
Вообще, в качестве вектора прерывания могут быть использованы любые данные (адрес подпрограммы, адрес перехода, значение смещения относительно начала таблицы прерываний, специальные инструкции и т.д.), которые позволяют непосредственно перейти к процедуре обработки прерывания, не затрачивая времени на поиск источника прерывания. Какие данные используются в качестве вектора прерывания и каким именно образом они используются зависит от способа реализации системы прерываний в соответствующем процессоре.
PIC vs . AVR vs. MSP vs mcs51. В контроллерах PIC 16 реализована одноуровневая система прерывания. При возникновении прерывания, процессор переходит по адресу 0x0004 (точка входа по прерыванию). Далее, после контекстного сохранения регистров, выполняется программный опрос признаков прерываний (поллинг ). Нужно также отметить, что при обнаружении источника прерывания требуется сбросить соответствующий установленный флажок запроса на прерывания.
В семействе PIC 18 используется как одноуровневая (в режиме совместимости с PIC 16), так и двухуровневая система прерываний. В режиме совместимости при возникновении прерывания процессор переходит к процедуре обработки прерывания по адресу 0x 000008 и далее все происходит аналогично PIC 16. При двухуровневой системе прерывания имеются два вектора перехода 0x 000008 и 0x 000018. Присвоение уровня каждому из имеющихся источников прерывания задается программным путем, с помощью соответствующих признаков. Способ организации системы прерывания (одно- или двухуровневая ) также определяется значением соответствующего разряда в регистре управления прерываниями.
В контроллерах семейства AVR реализована векторная система прерываний. При обнаружении прерывания, процессор сразу переходит по вектору прерывания к процедуре обработки прерываний от данного источника. Вектора прерываний расположены в начальных адресах программной памяти и представляют из себя команду перехода на обработчик прерывания. Количество векторов прерываний соответствует числу возможных источников прерываний, которые зависят от конкретного типа контроллера. Следует добавить, что сброс флажков запроса на прерывания происходит автоматически при переходе по вектору прерывания и выполнение каких-либо инструкций для этого не требуется.
В контроллерах семейства MSP 430 система прерываний также является векторной, т.е. каждому периферийному модулю соответствует свой вектор прерывания. Однако, это не исключает необходимости программного контроля (поллинга ), т.к. некоторые периферийные модули имеют множественные источники прерываний. Пример – прерывания от порта ввода/вывода. В данном случае имеется возможность программно разрешать прерывания от индивидуальных выводов порта. Даже в том случае, если разрешеныпрерывания от более, чем одного входа, они все будут иметь одинаковый вектор прерываний. Определить какой конкретно вход являлся источником прерывания можно только программно. Эта особенность также влияет и на сброс флагов прерываний – флаги прерывания с множественными источниками не сбрасываются автоматически в отличие от флагов прерывания с одним источником. Адрес и количество векторов прерывания зависят от конкретного типа контроллера. Вектора прерываний находятся в конце программной памяти (адресного пространства) и представляют из себя адрес обработчика прерывания.
В контроллерах семейства mcs 51 система прерываний также является векторной, но для вектора прерывания зарезервирован довольно большой обьем памяти (8 байт), что иногда бывает достаточно для его обработчика. Флаги прерывания сбрасываются автоматически при переходе к обработчику прерываний, если у прерывания возможен только один источник и несбрасываются если у прерывания может быть два и более источников. В последнем случае необходимо программно сбросить флаг вызвавший прерывание после выяснения причины прерывания (поллинга ). Вектора располагаются в начальных адресах программной памяти.
Приоритетные прерывания
Обычно, значимость тех или иных событий в системе неодинакова. Одни события более важны и требуют немедленной реакции, другие менее важны, и с ответом на них можно подождать. Естественно, что и соответствующие этим событиям прерывания должны иметь разный приоритет. При одновременном возникновении нескольких прерываний, процессор должен перейти к обработке прерывания, имеющего более высокий приоритет. Этот процесс происходит на аппаратном уровне ядра процессора и называется последовательностью опроса прерываний (interrupt polling sequence ).
PIC vs . AVR vs MSP vs. mcs51. В семействе PIC 16 приоритет опроса того или иного прерывания определяется очередностью опроса соответствующего флажка прерывания. Приоритет опроса прерывания будет выше утех прерываний, у которых флажки запросов на прерывания будут опрашиваться в первую очередь. Порядок опроса флажков признаков прерывания целиком определяется программой обработки прерывания и может быть изменен при ее изменении.
В контроллерах PIC 18 при двухуровневой системе прерывания более высокий уровень приоритетаимеют прерывания с вектором 0x 000008. В пределах одного уровня приоритетность прерывания определяется программно, так же как и у PIC 16.
В семействе AVR приоритета опроса жестко фиксирован и не может быть изменен. Чем меньше адрес вектора прерывания, тем выше уровень опроса прерывания ему соответствующего.
В семействе MSP 430 приоритет опроса также жестко фиксирован и неизменяем, но зависимость приоритета опроса прерывания обратная – чем выше адрес вектора прерывания, тем выше приоритет опроса данного прерывания.
В семействе mcs 51 приоритет опроса полностью анологичен контроллерам семейства AVR .
Вложенные прерывания
При вложенных прерываниях, процедура обработки текущего прерывания может быть прервана (отложена) при поступлении запроса на прерывание, имеющего более высокий уровень приоритета. После обработки прерывания с более высоким уровнем приоритета процессор возвращается к прерванной процедуре и продолжает обработку данного прерывания до ее окончания или до нового прерывания. Очевидно, что процедура обработки прерывания с более высоким уровнем может быть в свою очередь прервана прерыванием с еще более высоким уровнем приоритета и т.д. При этом прерывания, имеющие более низкий уровень приоритета по сравнению с текущим , обычно запрещаются (маскируются).
PIC vs . AVR . В семействе PIC16 процедура обработки любого прерывания начинается с одного и того же адреса и реализовать вложенные прерывания крайне затруднительно, если это вообще возможно.
В контроллерах PIC 18 при двухуровневой системе прерывания возможно прерывание процедур прерывания с низким уровнем приоритета прерываниями, имеющими более высокий уровень.
В семействе AVR в процедурах обработки прерываний глобальные прерывания автоматически запрещаются, и процедура обработки прерывания не может быть прервана. Тем не менее, если это необходимо, то можно в процедуре обработки прерыванияиспользовать инструкцию разрешения прерываний, разрешая тем самым вложенность прерываний. Естественно, что в этом случае сама эта процедура может быть прервана любым прерыванием, даже если оно имеет меньший уровень приоритета, по сравнению с текущим уровнем.
Аналогично организована обработка прерываний в семействе MSP . Следует, однако, отметить, что организация программы с вложенными прерываниями требует от программиста особого внимания. Более того, обработка прерывания внутри другого прерывания вообще является нежелательной и должна применяться только в крайних случаях. Ввиду того, что флаги прерываний устанавливаются аппаратно вне зависимости от того, разрешены ли прерывания глобально битом GIE , в большинстве случаев не представляет сложности обработка прерываний без использования вложенности.
В семействе mcs 51 аппаратно предусмотрена возможность вложенных прерываний. Для этого каждому типу прерывания может быть задан уровень приоритета high и прерывание с данным уровнем может прервать обработку другого прерывания с уровнем приоритета low . Приоритеты внутри одного уровня приоритета располагаются согласно последовательности опроса прерываний (interrupt polling sequence ).
| Наименование параметра | Значение |
| Тема статьи: | Прерывания. |
| Рубрика (тематическая категория) | Программирование |
Сторожевые таймеры.
Часто электрические помехи, производимые окружающим оборудованием, вызывают обращение микроконтроллера по неправильному адресу, после чего его поведение становится непредсказуемым (микроконтроллер ʼʼидет в разносʼʼ). Чтобы отслеживать такие ситуации в состав микроконтроллера часто включают сторожевые таймеры.
Это устройство вызывает сброс микроконтроллера, в случае если его содержимое не будет обновлено в течение определенного промежутка времени (обычно от десятков миллисекунд до нескольких секунд). В случае если изменение содержимого программного счетчика не соответствует заданной программе, то команда модификации сторожевого таймера не будет выполнена. В этом случае сторожевой таймер производит сброс микроконтроллера, устанавливая его в исходное состояние.
Многие разработчики не используют сторожевые таймеры в своих приложениях, так как не видят крайне важно сти их применения для борьбы с влиянием электрических помех, к примеру, при размещении микроконтроллера в электронно-лучевом дисплее вблизи от трансформатора, обеспечивающего гашение обратного хода луча, или рядом с катушками зажигания в автомобиле. В современной электронике вероятность возникновения электрических нарушений незначительна, хотя они иногда возникают в ситуациях, похожих на перечисленные выше.
Не рекомендуется использовать сторожевой таймер для маскирования программных проблем. Хотя данный таймер может уменьшить вероятность программных ошибок, однако вряд ли он обеспечит исключение всех возможных причин их возникновения. Вместо того, чтобы надеяться на предотвращение программных сбоев аппаратными средствами, лучше более тщательно протестировать программное обеспечение в различных ситуациях.
Многие пользователи считают, что прерывания - это та часть аппаратного обеспечения, которую лучше оставить в покое, так как их использование требует превосходного знания процессора для разработки программы обработки прерывания. В противном случае при возникновении прерывания система ʼʼзасыпаетʼʼ или ʼʼидет вразносʼʼ. Такое чувство обычно появляется у разработчика после опыта работы с прерываниями для персонального компьютера, который имеет ряд особенностей, усложняющих создание обработчика прерываний. Многие из этих проблем не имеют места в оборудовании, реализованном на базе микроконтроллеров. Использование в данном оборудовании прерываний может существенно упростить его разработку и применение.
В случае если вы никогда не имели дело с прерываниями, то у вас возникнет вопрос - что это такое? В компьютерной системе прерывание - это запуск специальной подпрограммы (называемой ʼʼобработчиком прерыванияʼʼ или ʼʼпрограммой обслуживания прерыванияʼʼ), который вызывается сигналом аппаратуры. На время выполнения этой подпрограммы реализация текущей программы останавливается. Термин ʼʼзапрос на прерываниеʼʼ (interrupt request) используется потому, что иногда программа отказывается подтвердить прерывание и выполнить обработчик прерывания немедленно (рис 2.19).
Прерывания в компьютерной системе аналогичны прерываниям в повседневной жизни. Классический пример такого прерывания - телефонный звонок во время просмотра телевизионной передачи. Когда звонит телефон, у вас есть три возможности. Первый - проигнорировать звонок. Второй - ответить на звонок, но сказать, что вы перезвоните позже. Третий - ответить на звонок, отложив все текущие дела. В компьютерной системе также имеются три подобных ответа͵ которые бывают использованы в качестве реакции на внешний аппаратный запрос.
Первый возможный ответ - ʼʼне реагировать на прерывание, пока не завершится выполнение текущей задачиʼʼ - реализуется путем запрещения (маскирования) обслуживания запроса прерывания. После завершения задачи возможен один из двух вариантов: сброс маски и разрешение обслуживания, что приведет к вызову обработчика прерывания, или анализ значения битов (ʼʼполлингʼʼ). указывающих на поступление запросов прерывания и непосредственное выполнение программы обслуживания без вызова обработчика прерывания. Такой метод обработки прерываний используется, когда требуется обеспечить заданное время выполнения основной программы, так как любое прерывание может нарушить реализацию крайне важно го интерфейса.

Рис. 2.18 - Выполнение прерывания.
Не рекомендуется долгое маскирование прерываний, так как в течение этого времени может произойти наложение нескольких событий, вызывающих прерывания, а распознаваться будет только одно. Допустимая продолжительность маскирования зависит от конкретного применения микроконтроллера, типа и частоты следования таких событий. Не рекомендуется запрещать прерывания на время большее, чем половина минимального ожидаемого периода следования событий, запрашивающих прерывания.
Обработчик прерывания всегда обеспечивает следующую последовательность действий:
2. Сбросить контроллер прерываний и оборудование, вызвавшее запрос.
3. Обработать данные.
4. Восстановить содержимое регистров контекста.
5. Вернуться к прерванной программе.
Регистры контекста - это регистры, определяющие текущее состояние выполнения основной программы. Обычно к их числу относятся программный счетчик, регистры состояния и аккумуляторы. Другие регистры процессора, такие как индексные регистры, бывают использованы в процессе обработки прерывания, в связи с этим их содержимое также крайне важно сохранить. Все остальные регистры являются специфическими для конкретного микроконтроллера и его применения.
После сброса в исходное состояние контроллер прерываний готов воспринимать следующий запрос, а оборудование, вызывающее прерывание, готово посылать запрос, когда возникают соответствующие причины. В случае если поступит новый запрос прерывания, то регистр маскирования прерываний процессора предотвратит обработку прерывания, но регистр состояния прерываний зафиксирует данный запрос, который будет ожидать своего обслуживания. После завершения обработки текущего прерывания маска прерываний будет сброшена, и вновь поступивший запрос поступает на обработку.
Вложенные прерывания сложны для реализации некоторыми типами микроконтроллеров, которые не имеют стека. Эти прерывания могут также вызвать проблемы, связанные с переполнением стека. Проблема переполнения актуальна для микроконтроллеров из-за ограниченного объёма их памяти данных и стека: последовательность вложенных прерываний может привести к тому, что в стек будет помещено больше данных, чем это допустимо.
Наконец, прерывание обработано. Второй пример с телевизором показывает, что можно быстро отреагировать на запрос прерывания, приняв необходимые данные, которые будут затем использованы после решения текущей задачи. В микроконтроллерах это реализуется путем сохранения поступивших данных в массиве памяти и последующей их обработки, когда выполнение исходной программы будет завершено. Такой способ обслуживания является хорошим компромиссом между немедленной полной обработкой прерывания, которая может потребовать много времени, и игнорированием прерывания, что может привести к потере информации о событии, вызвавшем прерывание.
Восстановление регистров контекста и выполнение команды возврата из прерывания переводит процессор в состояние, в котором он находился до возникновения прерывания.
Рассмотрим, что происходит с содержимым различных регистров при обработке прерывания. Содержимое регистра состояния обычно автоматически сохраняется вместе с содержимым программного счетчика перед обработкой прерывания. Это избавляет от крайне важно сти сохранять его в памяти программными средствами с помощью команд пересылки, а затем восстанавливать при возврате к исходной программе. При этом такое автоматическое сохранение реализуется не во всех типах микроконтроллеров, в связи с этим организации обработки прерываний следует уделить особое внимание.
В случае если содержимое регистра состояния сохраняется перед началом выполнения обработчика прерывания, то по команде возврата производится его автоматическое восстановление.
В случае если содержимое других регистров процессора изменяется при выполнении обслуживания прерывания, то оно также должно быть сохранено в памяти до изменения и восстановлено перед возвратом в основную программу. Обычно принято сохранять все регистры процессора, чтобы избежать непредсказуемых ошибок, которые очень трудно локализовать.
Адрес, который загружается в программный счетчик при переходе к обработчику прерывания, принято называть ʼʼвектор прерыванияʼʼ. Существует несколько типов векторов. Адрес, который загружается в программный счетчик при запуске микроконтроллера (reset) принято называть ʼʼвектор сбросаʼʼ. Для различных прерываний бывают заданы разные вектора, что избавляет программу обслуживания от крайне важно сти определять причину прерывания. Использование различными прерываниями одного вектора обычно не вызывает проблем при работе микроконтроллеров, так как чаще всего микроконтроллер исполняет одну единственную программу. Этим микроконтроллер отличается от персонального компьютера, в процессе эксплуатации которого могут добавляться различные источники прерываний. (В случае если вы когда-либо подключали два устройства к портам СОМ1 и COM3, то вы представляете, о чем идет речь). В микроконтроллере, где аппаратная часть хорошо известна, не должно возникнуть каких-либо проблем при совместном использовании векторов прерываний.
Последнее, что осталось рассмотреть, - это программные прерывания. Существуют процессорные команды, которые бывают использованы для имитации аппаратных прерываний. Наиболее очевидное использование этих команд - это вызов системных подпрограмм, которые располагаются в произвольном месте памяти, или требуют для обращения к ним межсегментных переходов. Эта возможность реализована в микропроцессорах семейства Intel i86 и используется в базовой системе ввода-вывода BIOS (Basic Input/Output System) и операционной системе DOS персональных компьютеров для вызова системных подпрограмм без крайне важно сти фиксирования точки входа. Вместо этого используются различные вектора прерываний, выбирающие команду, которая должна выполняться, когда происходит такое программное прерывание.
Возможно после прочтения этой главы механизм прерываний станет для Вас более понятным или, наоборот. Вы только еще больше запутаетесь. При описании каждого микроконтроллера будет показано, как использование прерываний может упростить его применение.
Прерывания. - понятие и виды. Классификация и особенности категории "Прерывания." 2017, 2018.
Прерывание - это изменение естественного порядка выполнения программы, которое связано с необходимостью реакции системы на работу внешних устройств, а также на ошибки и особые ситуации, возникшие при выполнении программы. При этом вызывается специальная программа - обработчик прерываний , специфическая для каждой возникшей ситуации, после выполнения которой возобновляется работа прерванной программы.
Механизм прерывания обеспечивается соответствующими аппаратно-программными средствами компьютера.
Классификация прерываний представлена на рис. 7.1 .
Рис.
7.1.
Запросы аппаратных прерываний возникают асинхронно по отношению к работе микропроцессора и связаны с работой внешних устройств.
Запрос от немаскируемых прерываний поступает на вход NMI микропроцессора и не может быть программно заблокирован. Обычно этот вход используется для запросов прерываний от схем контроля питания или неустранимых ошибок ввода/вывода.
Для запросов маскируемых прерываний используется вход INT микропроцессора. Обработка запроса прерывания по данному входу может быть заблокирована сбросом бита IF в регистре флагов микропроцессора.
Программные прерывания , строго говоря, называются исключениями или особыми случаями. Они связаны с особыми ситуациями, возникающими при выполнении программы (отсутствие страницы в оперативной памяти, нарушение защиты, переполнение ), то есть с теми ситуациями, которые программист предвидеть не может, либо с наличием в программе специальной команды INT n, которая используется программистом для вызова функций операционной системы либо BIOS , поддерживающих работу с внешними устройствами. В дальнейшем при обсуждении работы системы прерываний мы будем употреблять единый термин " прерывание " для аппаратных прерываний и исключений, если это не оговорено особо.
Программные прерывания делятся на следующие типы.
Нарушение (отказ) - особый случай, который микропроцессор может обнаружить до возникновения фактической ошибки (например, отсутствие страницы в оперативной памяти); после обработки нарушения программа выполняется с рестарта команды, приведшей к нарушению.
Ловушка - особый случай, который обнаруживается после окончания выполнения команды (например, наличие в программе команды INT n или установленный флаг TF в регистре флагов ). После обработки этого прерывания выполнение программы продолжается со следующей команды.
Авария ( выход из процесса) - столь серьезная ошибка, что некоторый контекст программы теряется и ее продолжение невозможно. Причину аварии установить нельзя, поэтому программа снимается с обработки. К авариям относятся аппаратные ошибки, а также несовместимые или недопустимые значения в системных таблицах.
Порядок обработки прерываний
Прерывания и особые случаи распознаются на границах команд, и программист может не заботиться о состоянии внутренних рабочих регистров и устройств конвейера.
Реагируя на запросы прерываний, микропроцессор должен идентифицировать его источник, сохранить минимальный контекст текущей программы и переключиться на специальную программу - обработчик прерывания. После обслуживания прерывания МП возвращается к прерванной программе, и она должна возобновиться так, как будто прерывания не было.
Обработка запросов прерываний состоит из:
- "рефлекторных" действий процессора, которые одинаковы для всех прерываний и особых случаев и которыми программист управлять не может;
- выполнения созданного программистом обработчика.
Для того чтобы микропроцессор мог идентифицировать источник прерывания и найти обработчик, соответствующий полученному запросу, каждому запросу прерывания присвоен свой номер (тип прерывания ).
Тип прерывания для программных прерываний вводится изнутри микропроцессора; например, прерывание по отсутствию страницы в памяти имеет тип 14. Для прерываний, вызываемых командой INT n, тип содержится в самой команде. Для маскируемых аппаратных прерываний тип вводится из контроллера приоритетных прерываний по шине данных . Немаскируемому прерыванию назначен тип 2.
Всего микропроцессор различает 256 типов прерываний . Таким образом, все они могут быть закодированы в 1 байте.
"Рефлекторные" действия микропроцессора по обработке запроса прерывания выполняются аппаратными средствами МП и включают в себя:
- определение типа прерывания ;
- сохранение контекста прерываемой программы (некоторой информации, которая позволит вернуться к прерванной программе и продолжить ее выполнение). Всегда автоматически сохраняются как минимум регистры EIP и CS , определяющие точку возврата в прерванную программу, и регистр флагов EFLAGS . Если вызов обработчика прерывания проводится с использованием шлюза задачи, то в памяти полностью сохраняется сегмент состояния TSS прерываемой задачи;
- определение адреса обработчика прерывания и передача управления первой команде этого обработчика.
После этого выполняется программа - обработчик прерывания , соответствующая поступившему запросу. Эта программа пишется и размещается в памяти прикладным или системным программистом. Обработчик прерывания должен завершаться командой I RET , по которой автоматически происходит переход к продолжению выполнения прерванной программы с восстановлением ее контекста.
Для вызова обработчика прерывания микропроцессор при работе в реальном режиме использует таблицу векторов прерываний , а в защищенном режиме - таблицу дескрипторов прерываний .

Рис. 7.3.
Содержимое регистра IDTr не сохраняется в сегментах TSS и не изменяется при переключении задачи. Программы не могут обратиться к IDT , так как единственный бит TI индикатора таблицы в селекторе сегмента обеспечивает выбор только между таблицами GDT и LDT .
Максимальный предел таблицы дескрипторов прерываний составляет 256*8 - 1 = 2047.
Можно определить предел меньшим, но это не рекомендуется. Если происходит обращение к дескриптору вне пределов IDT , процессор переходит в режим отключения до получения сигнала по входу NMI или сброса.
В IDT могут храниться только дескрипторы следующих типов:
- шлюз ловушки ,
- шлюз прерывания, шлюз задачи.